In the ever-evolving landscape of InsurTech, cross-selling is a literal goldmine. Utilizing Opus 4.6 and Agentic Coding, I have constructed a sophisticated "Insurance Cross-Sell Prediction Model" implementation pipeline, covering everything from memory-optimized data loading to complex feature engineering. Let’s dive in!
1. Agentic Coding with Opus 4.6
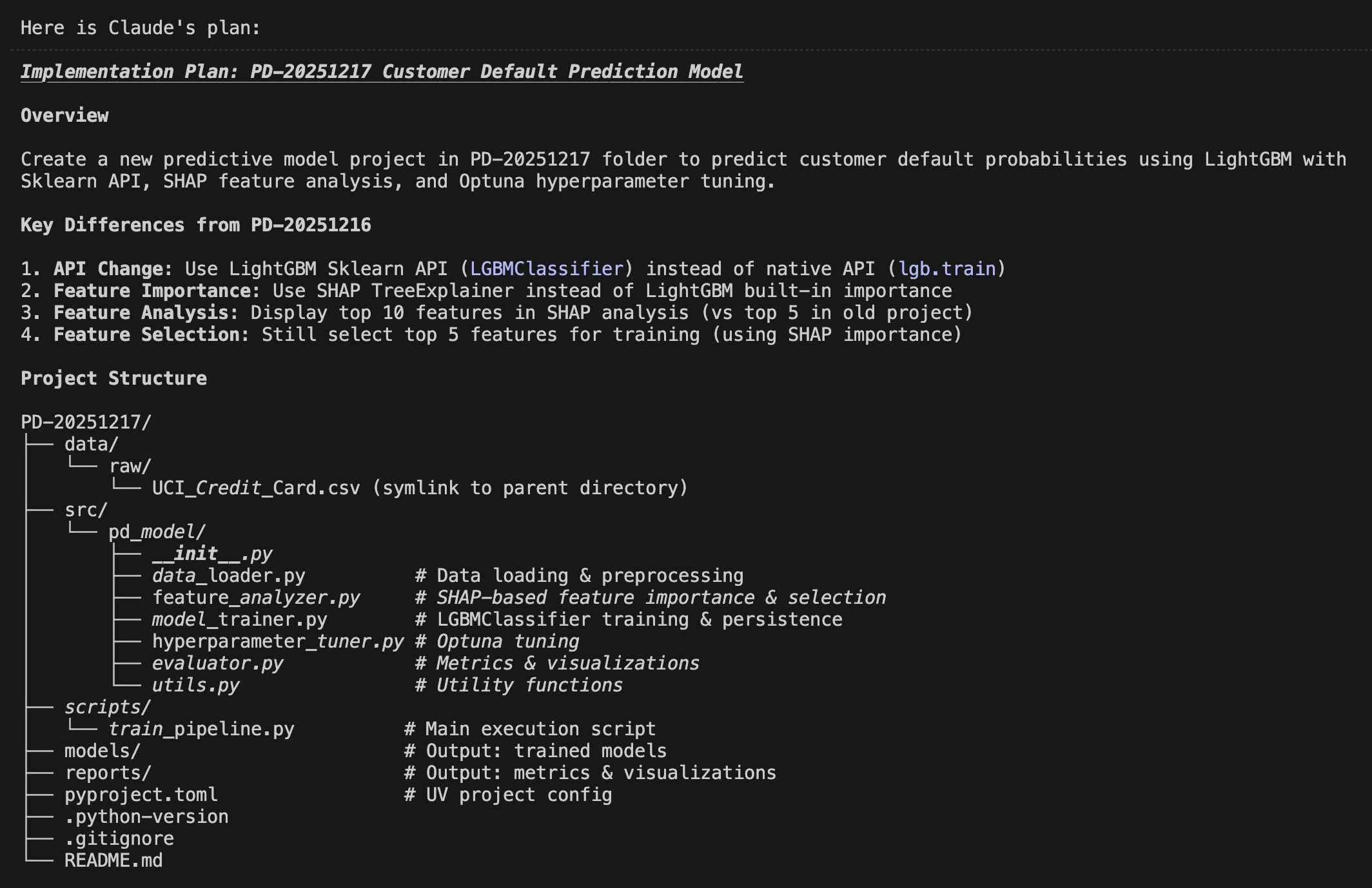
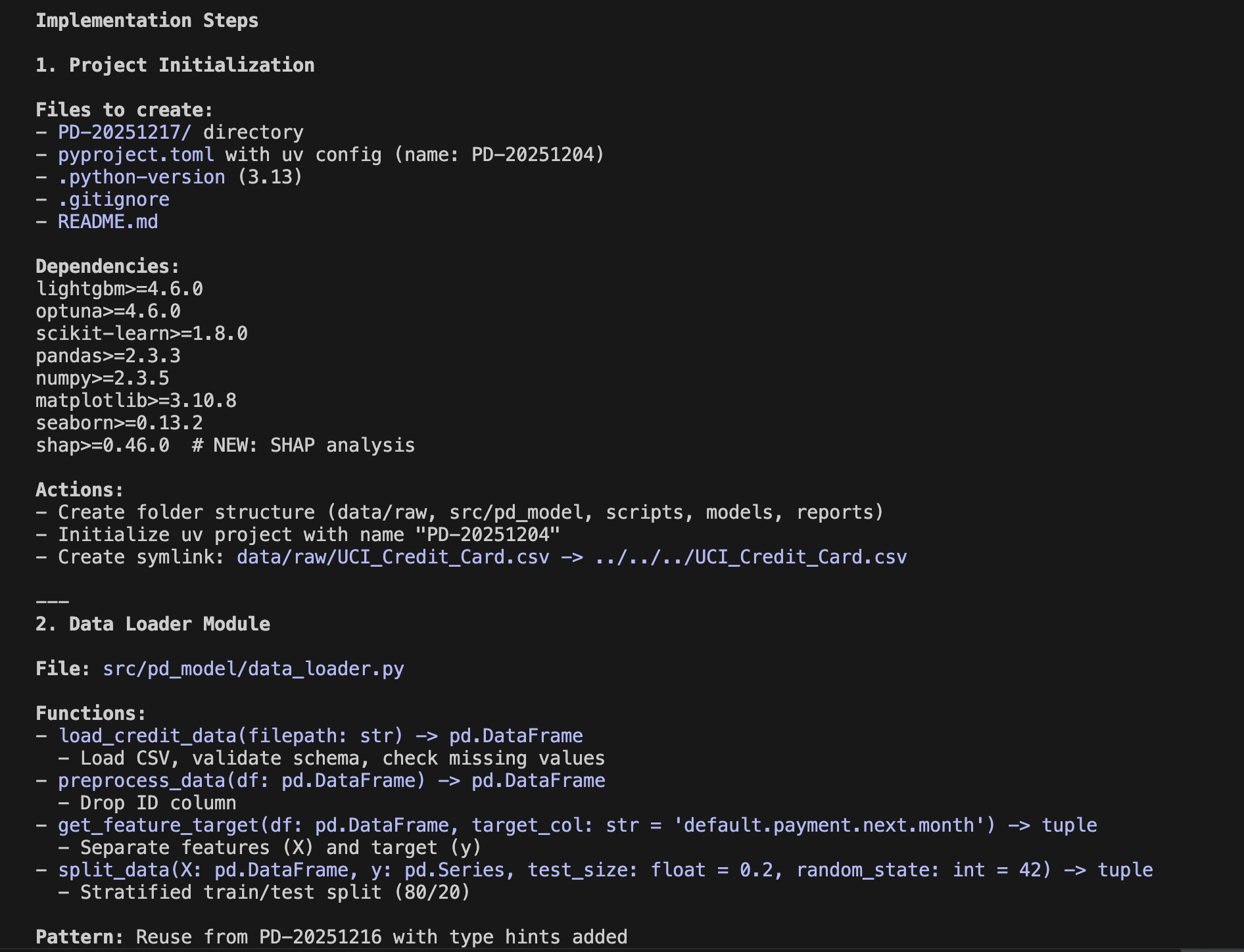
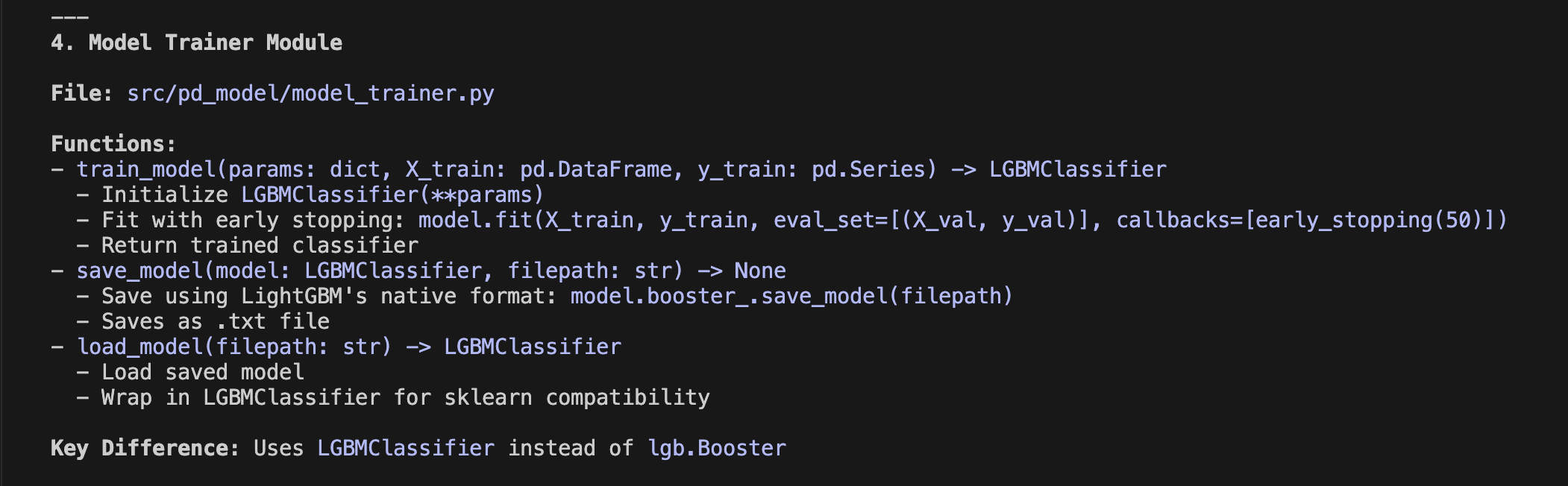
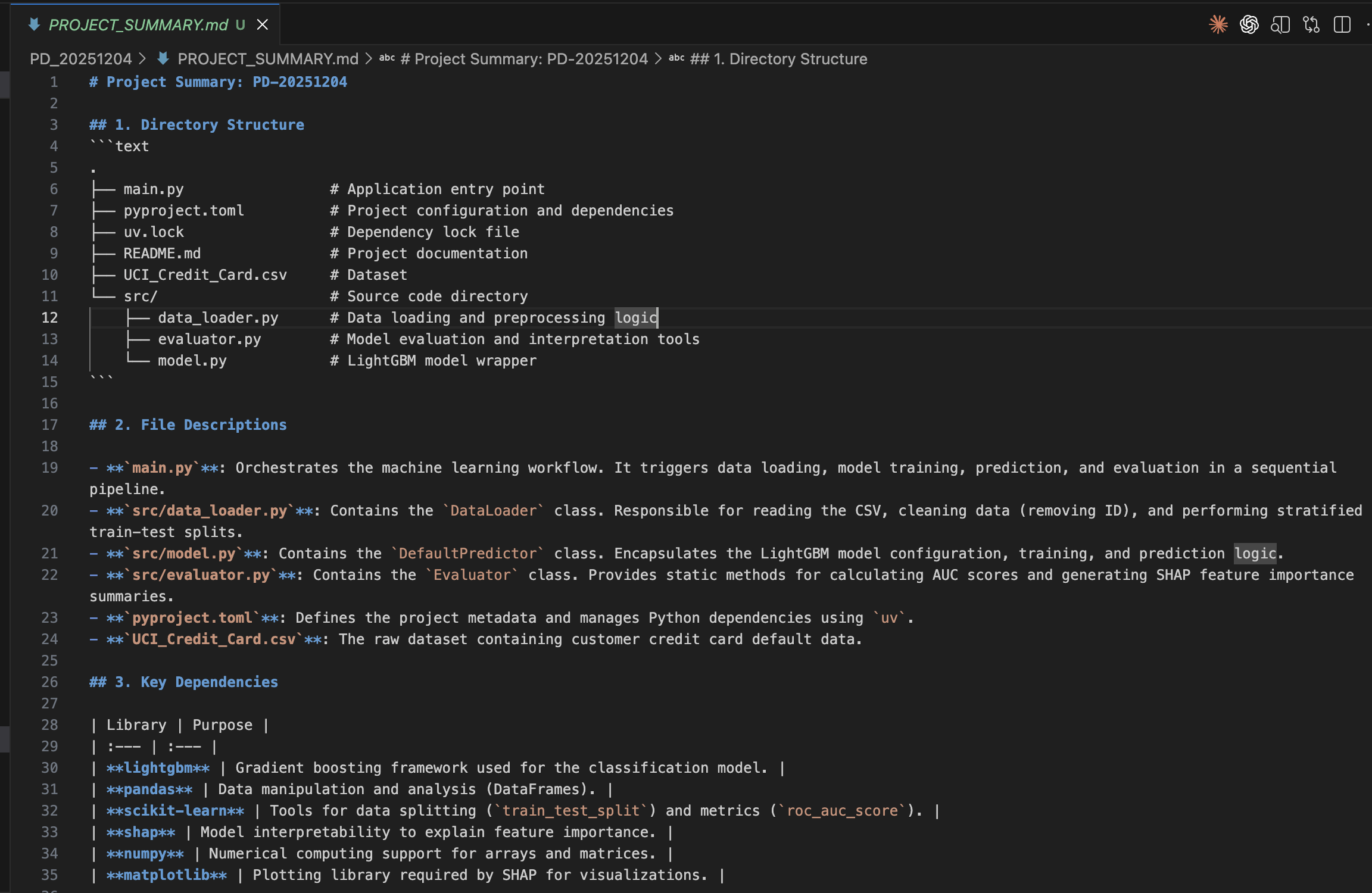
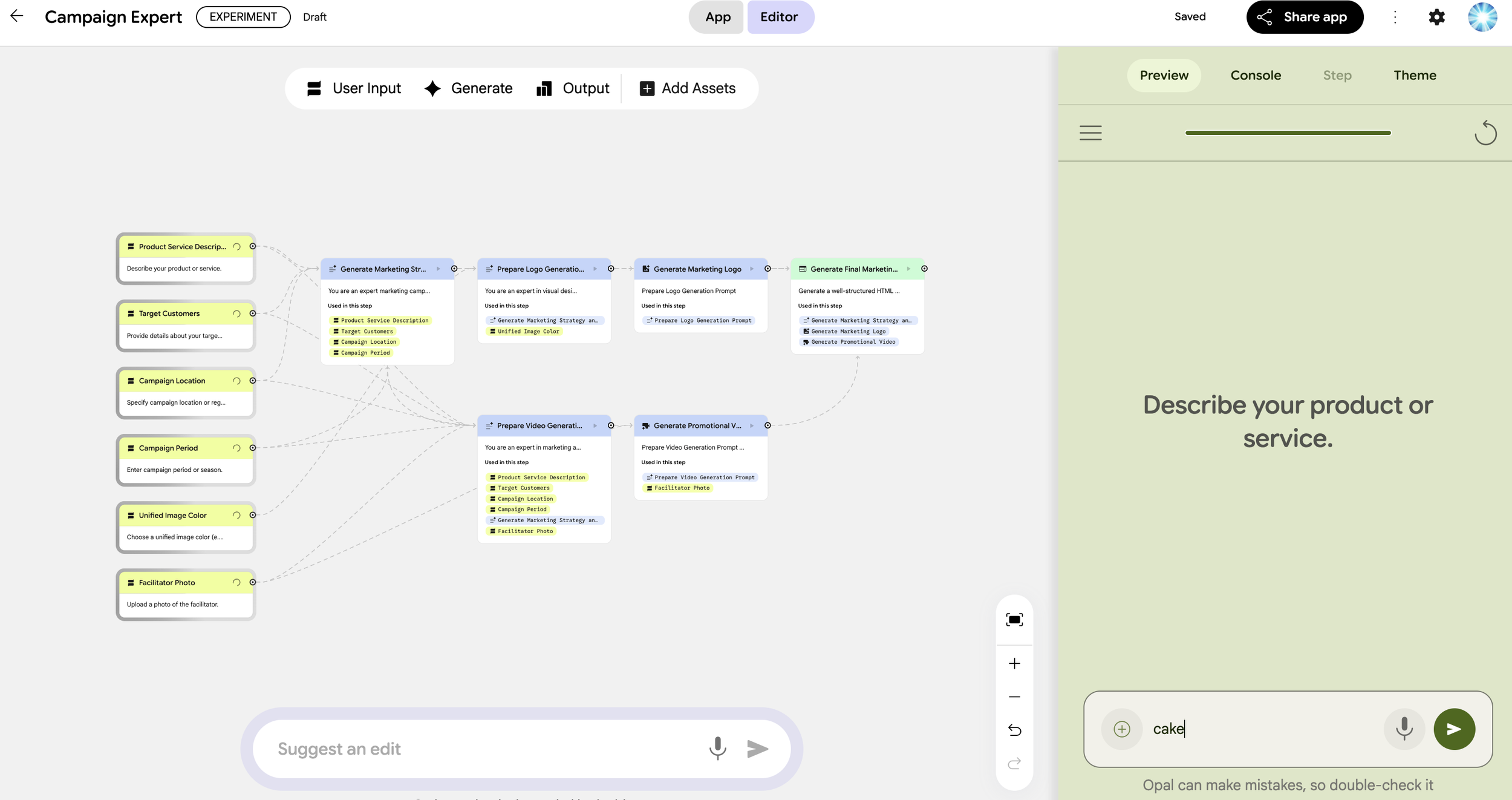
Unlike traditional coding, Agentic Coding with Opus 4.6 (1) allows the AI to function as an autonomous engineer. It goes beyond writing snippets; it manages directory structures, ensures memory efficiency for datasets of 11.5 million rows, and completes a production-ready Streamlit dashboard.
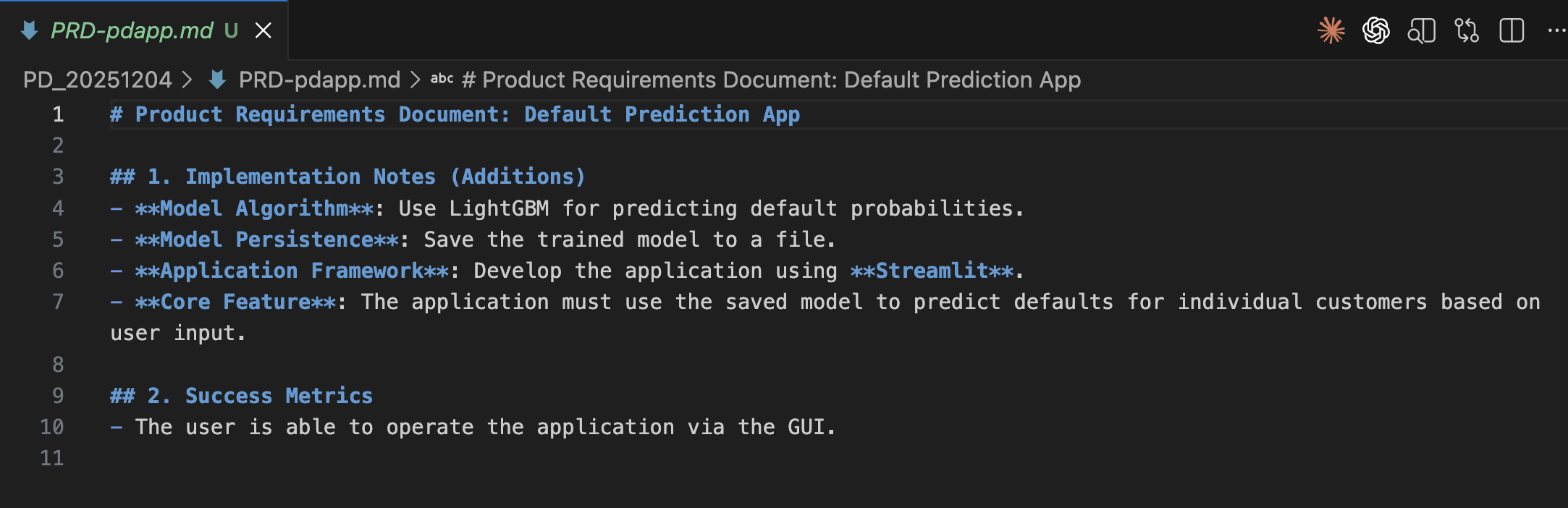
In this process, my role was simply to write the "Product Requirement Document (PRD)”—a document in natural language (Japanese or English) defining what I wanted to build. No Python knowledge was required on my part. By putting Claude Code into plan mode, an implementation blueprint is automatically generated, allowing me to verify the coding logic before Opus 4.6 executes it. While I monitored the progress, I never had to write a single line of code myself. Truly remarkable.
2. Project Overview
This project features a robust ecosystem designed for real-world application:
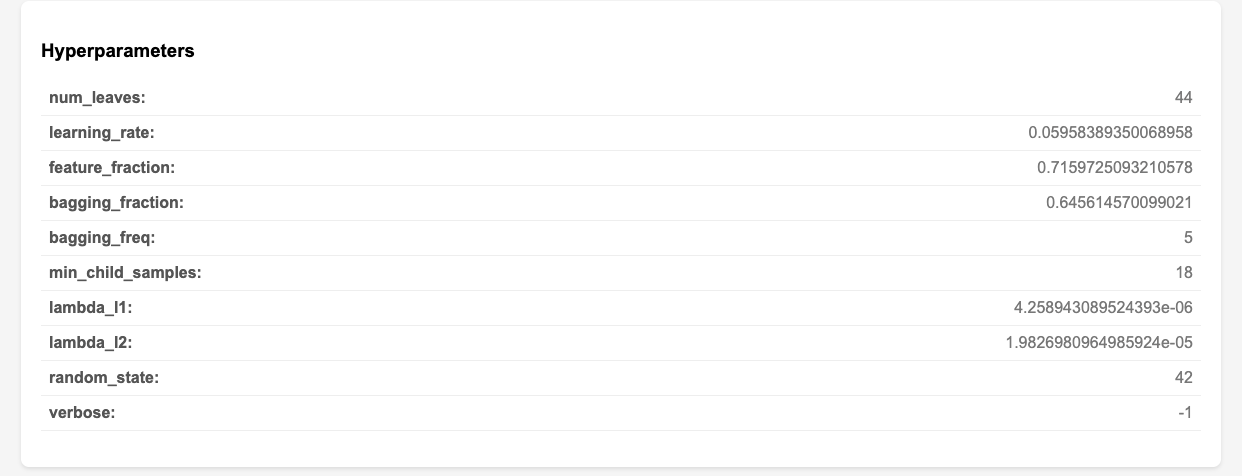
LightGBM + Optuna: Automated hyperparameter optimization to maximize AUC.
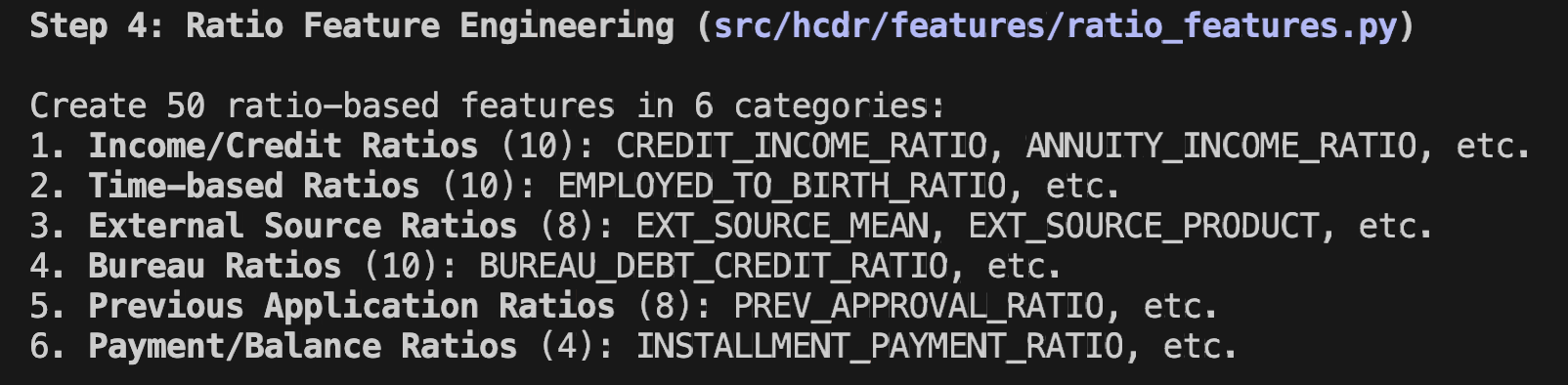
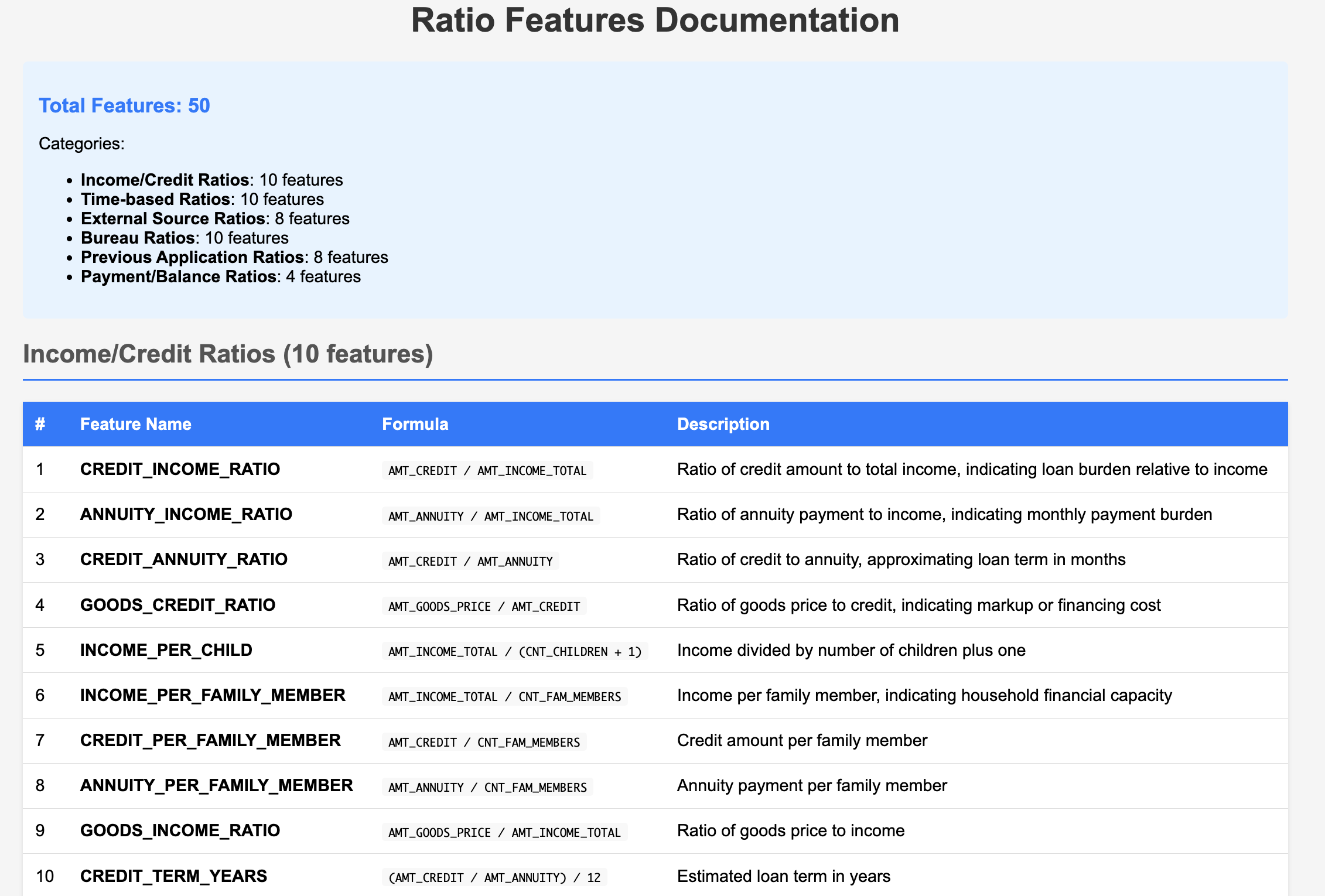
50 Ratio-Based Features: Generation of 50 unique indicators to capture hidden customer behavior patterns.
Explainability via SHAP: Implementation of SHAP values to visualize why a specific customer is likely to purchase.
The data was sourced from a Kaggle competition regarding automobile insurance cross-selling (2).

Kaggle competition regarding automobile insurance cross-selling
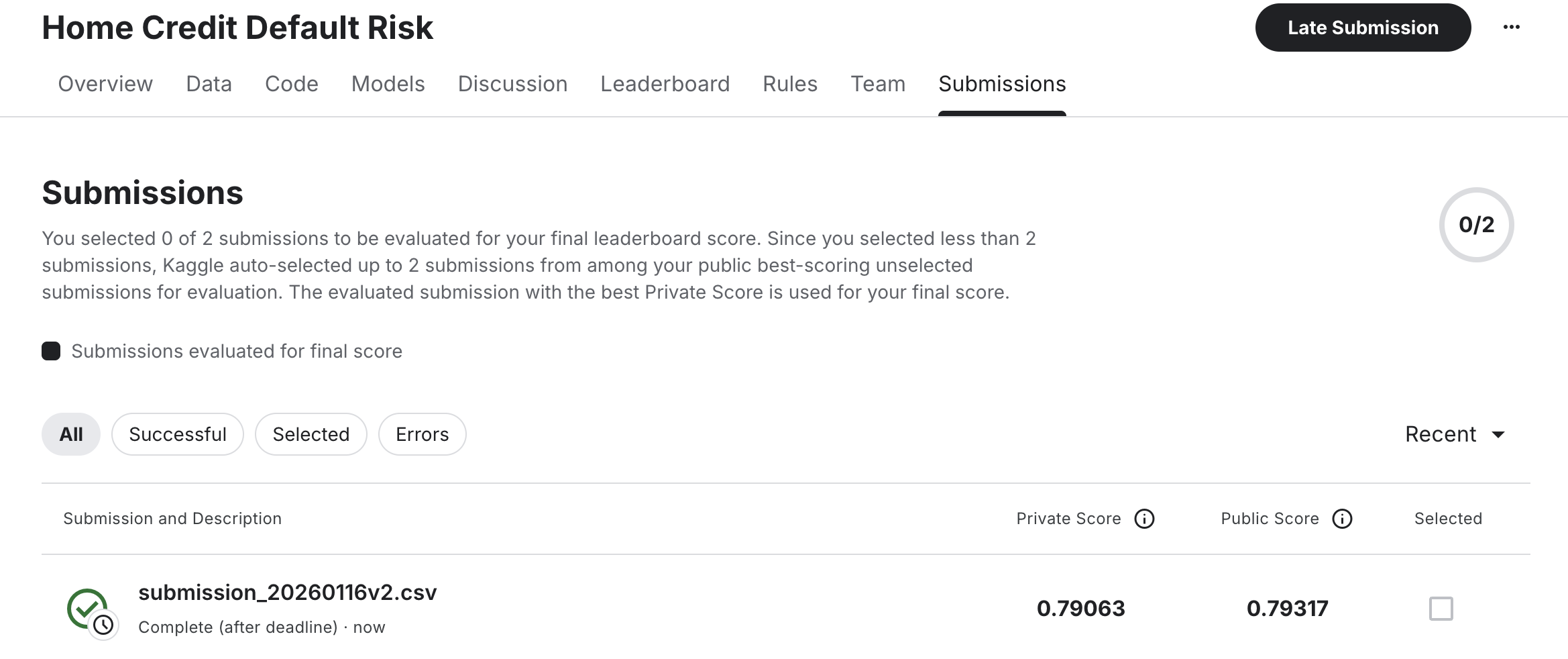
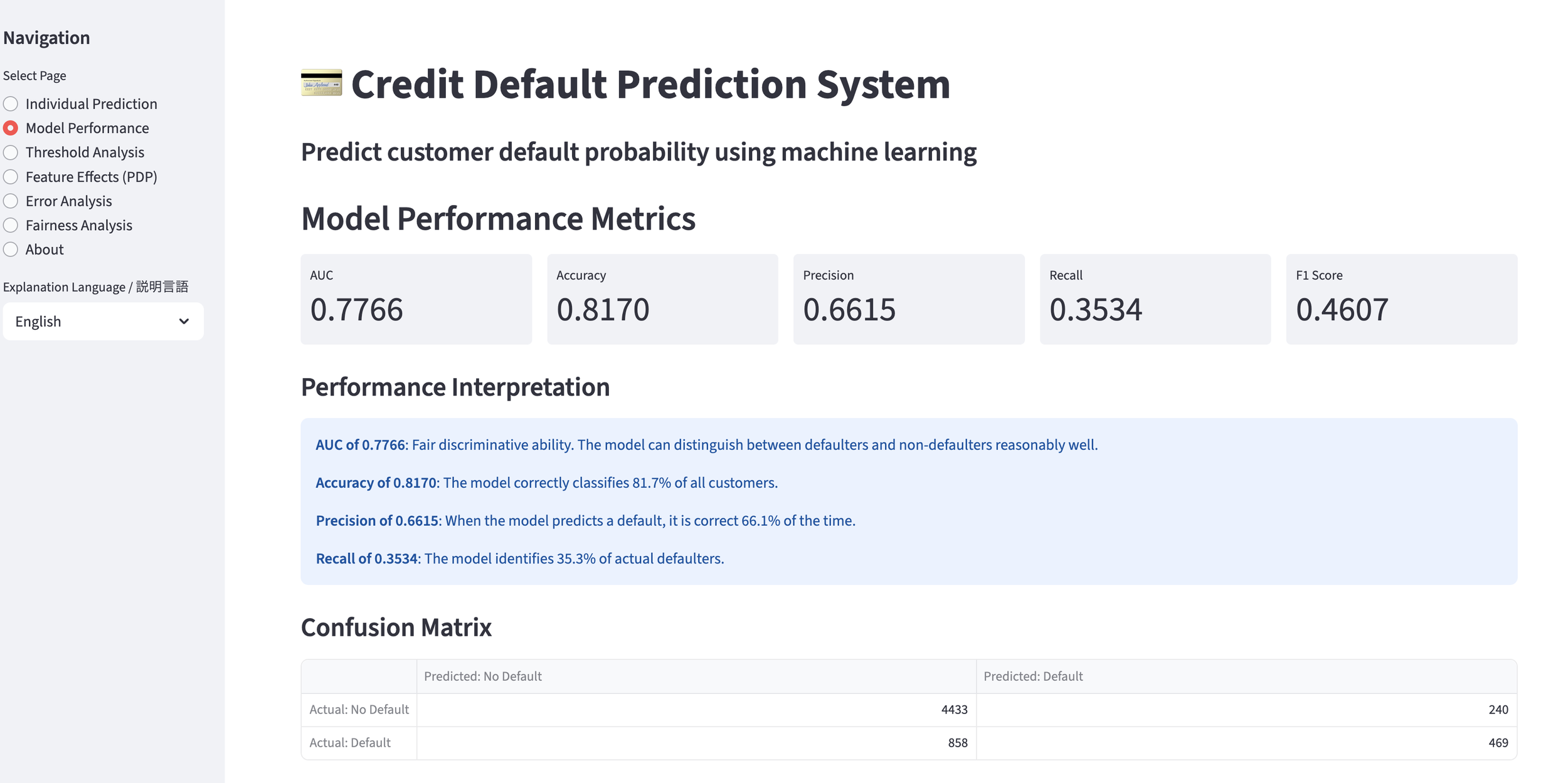
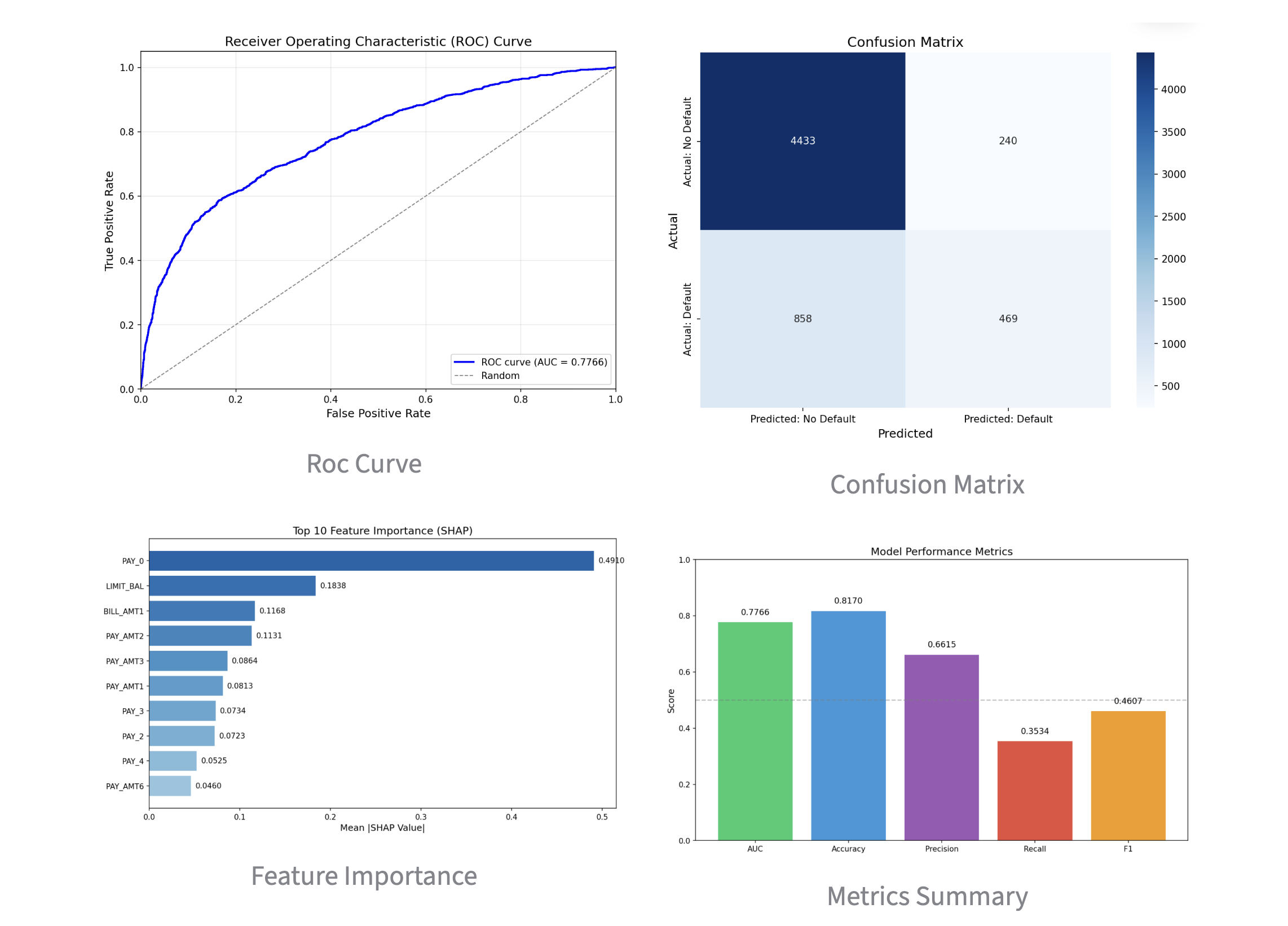
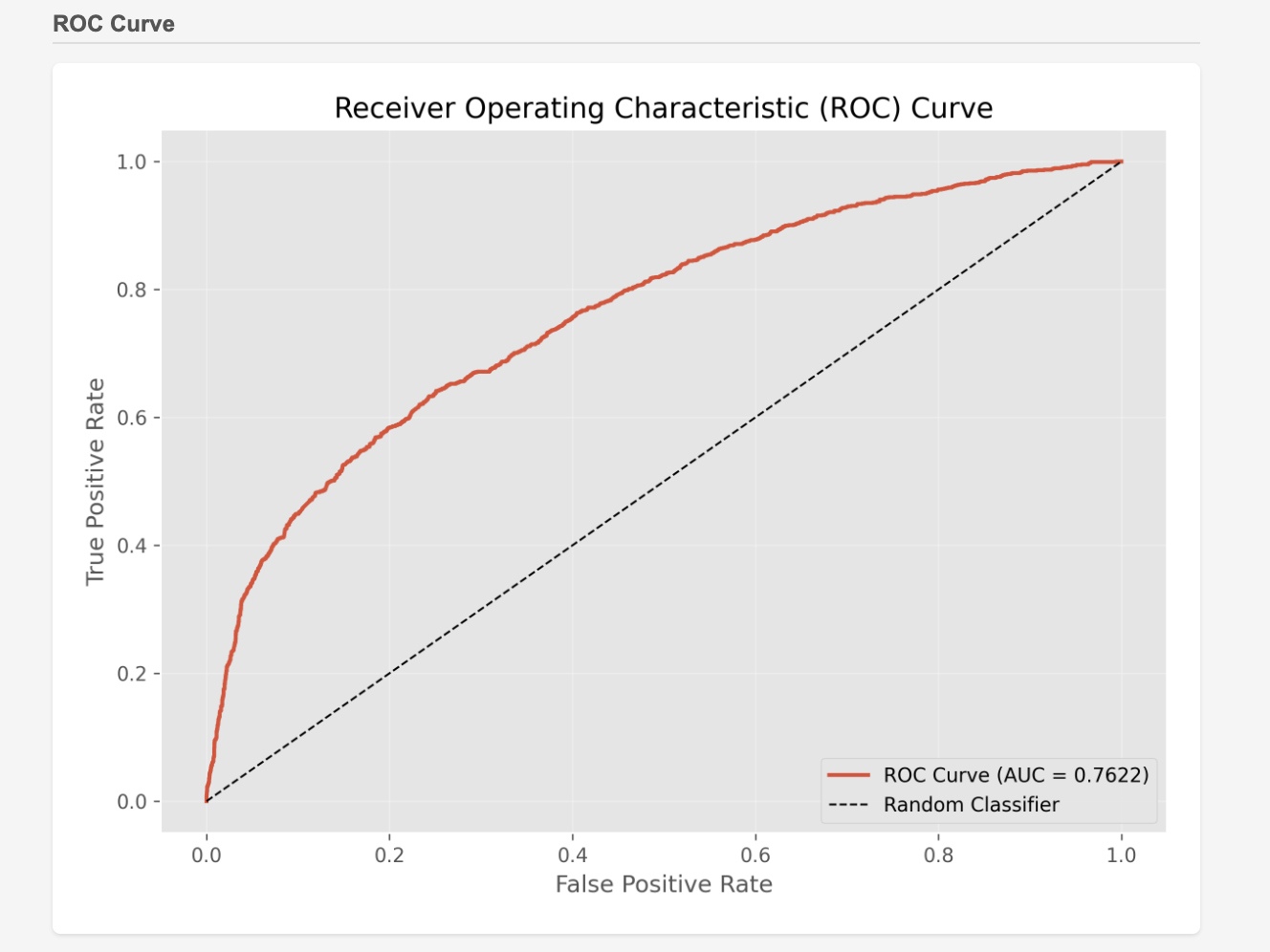
Performance Results: When evaluating the model built via Opus 4.6 Agentic Coding on the Kaggle leaderboard, it achieved a high score of AUC = 0.88343. This level of accuracy is more than sufficient for practical business use.
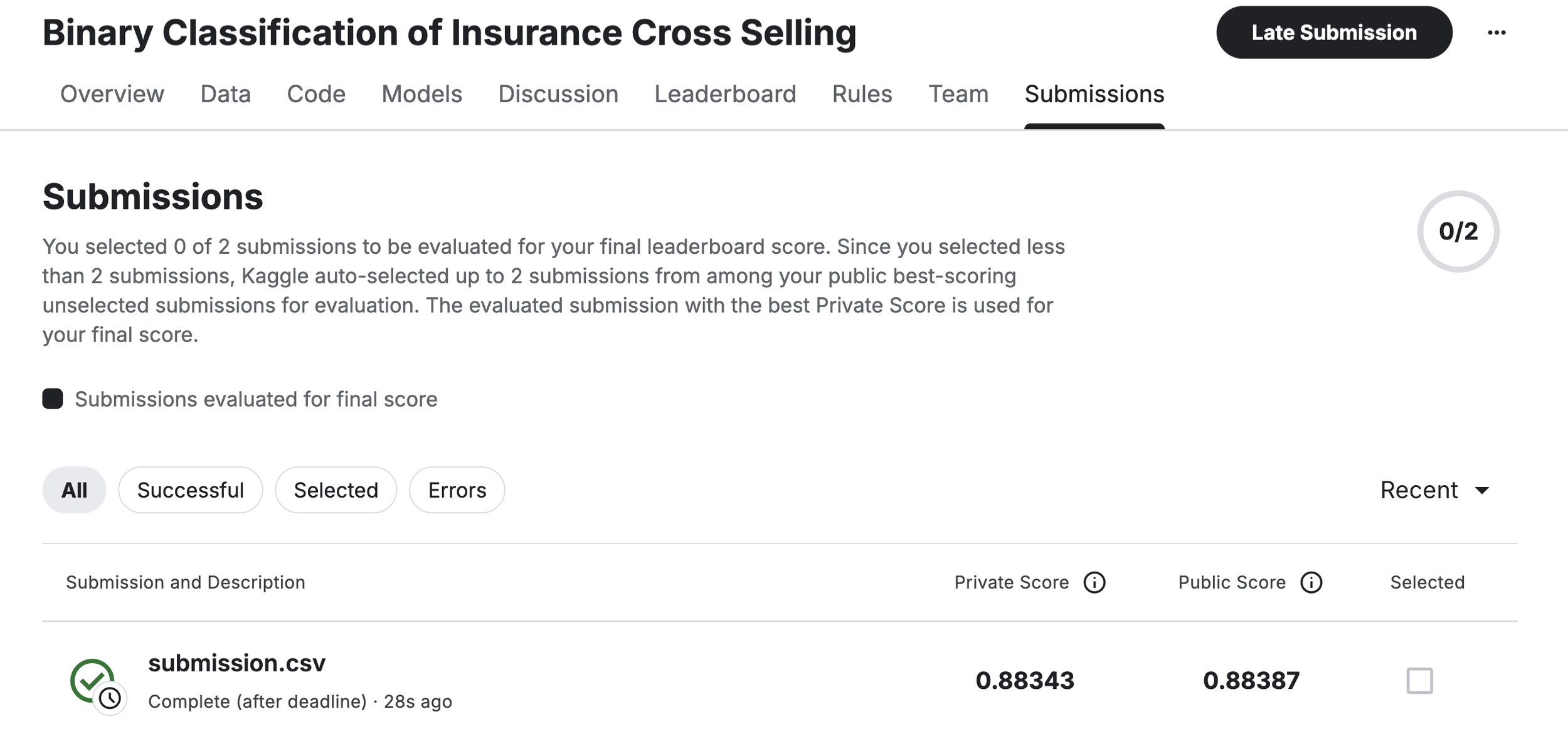
Kaggle leaderboard
3. Key Features of the Implementation
The model provides two primary functions: individual customer prediction and total customer portfolio analysis.
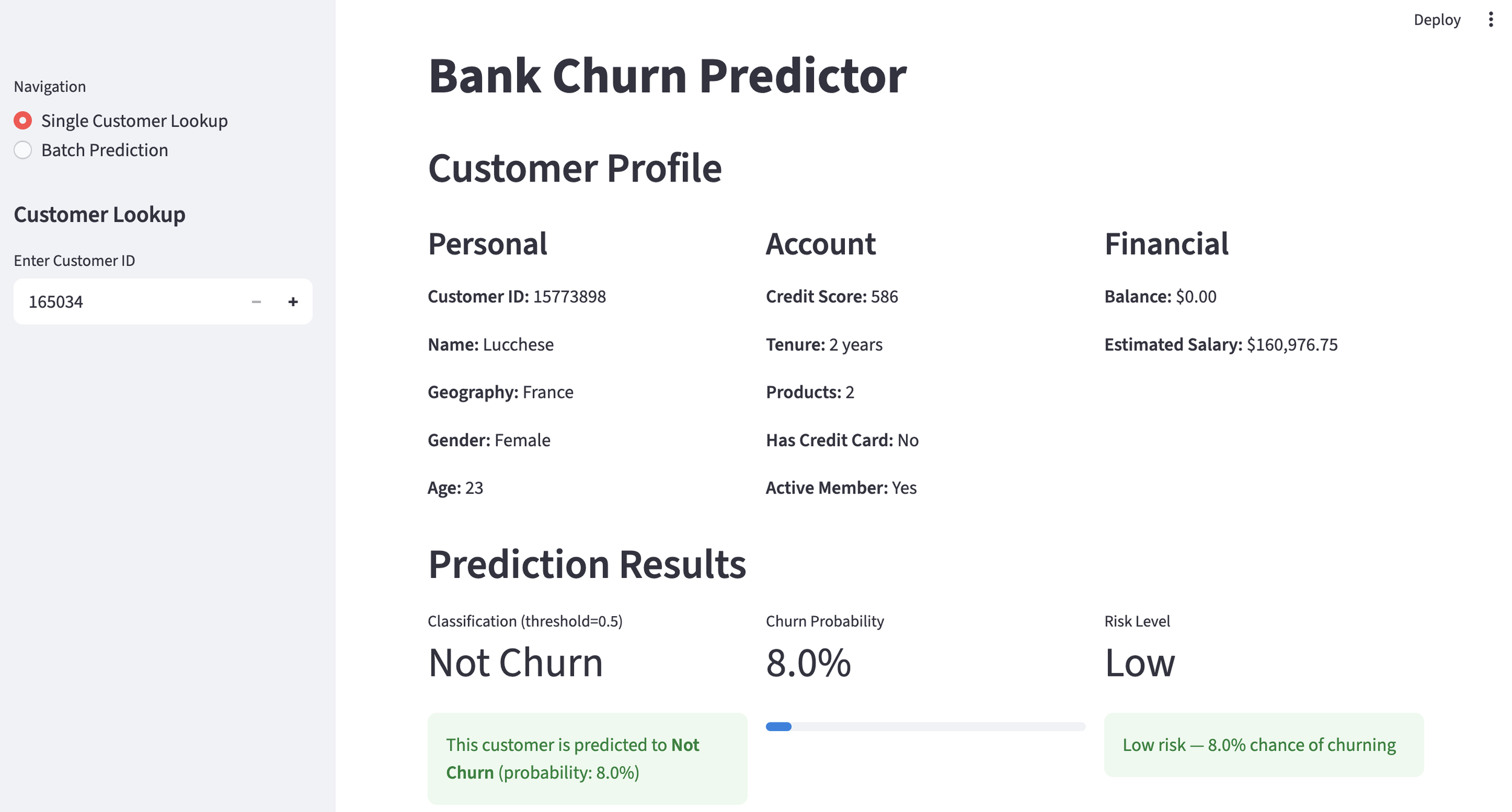
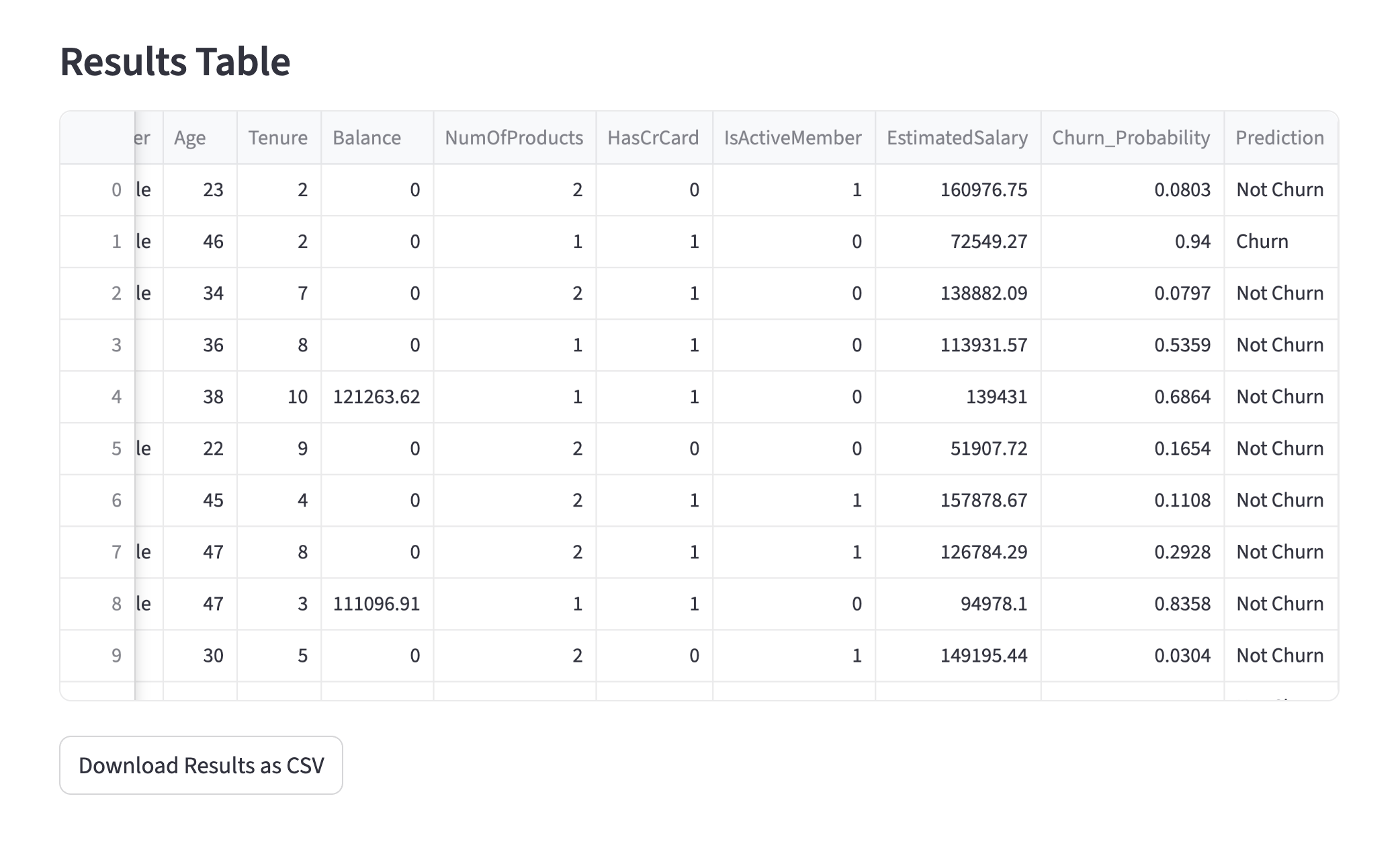
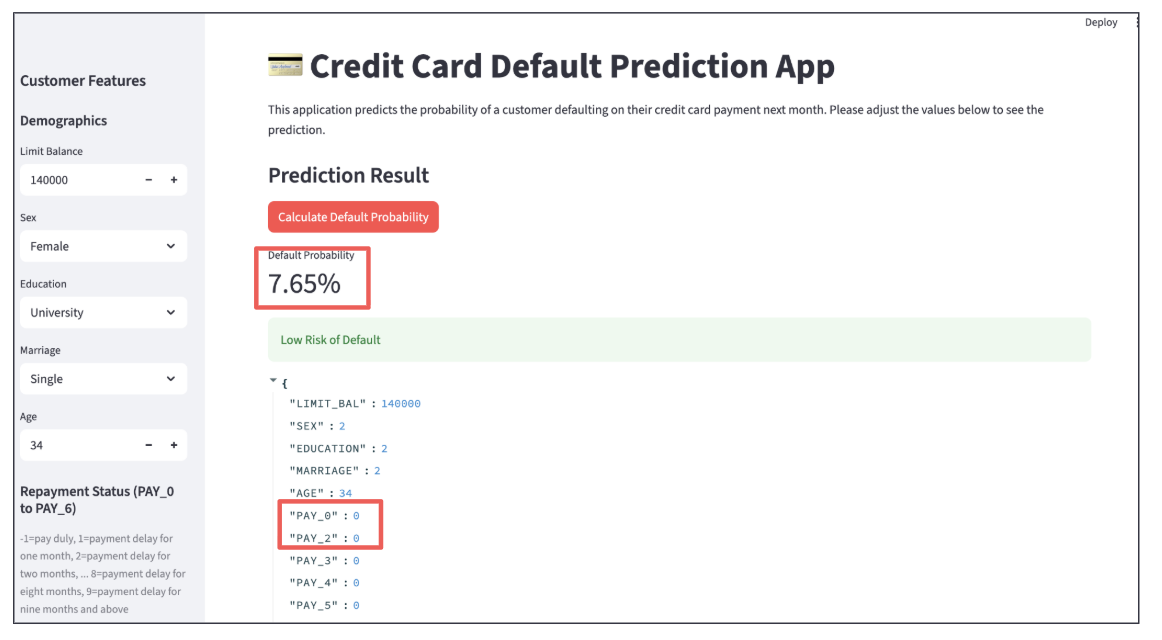
Individual Prediction
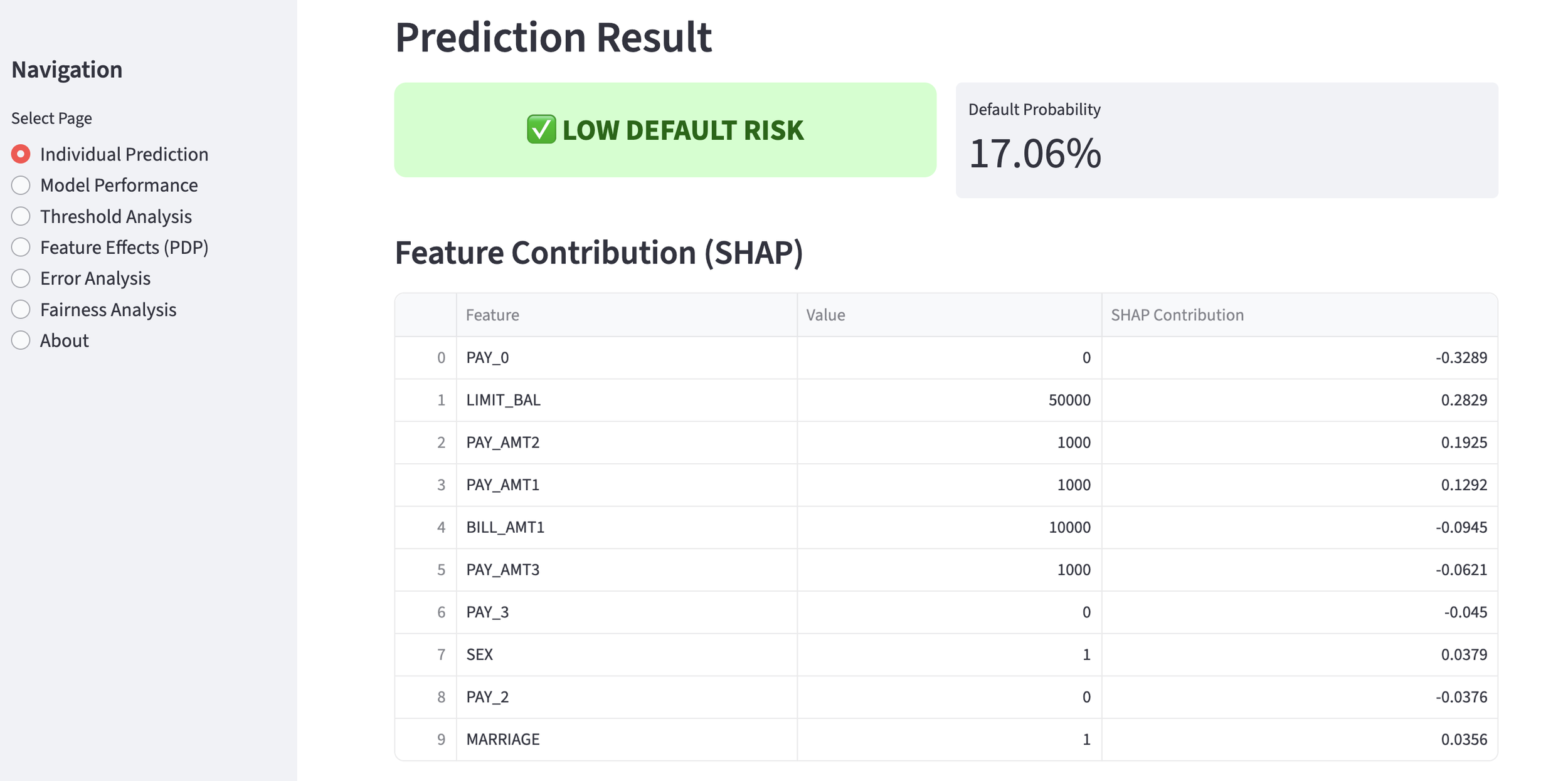
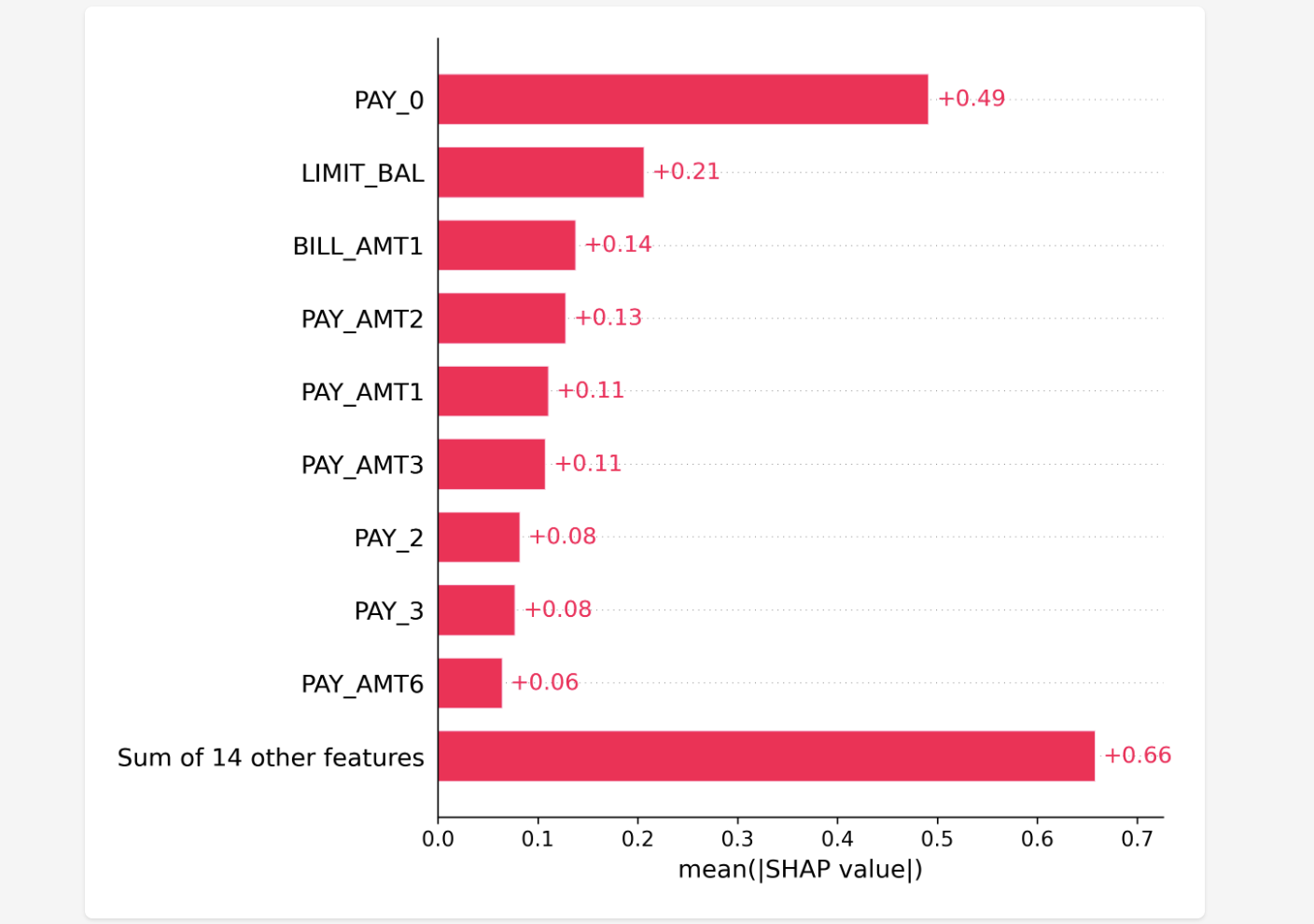
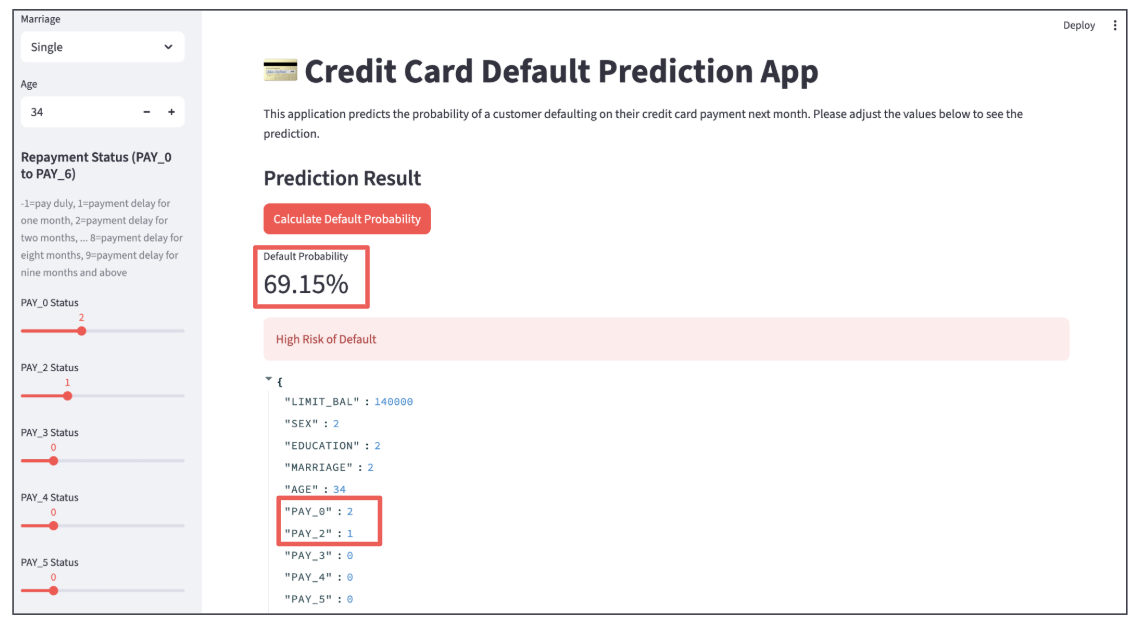
We set the threshold for a "successful" cross-sell at a probability of 35% or higher. Below is an example of a customer predicted to be a successful cross-sell target. To avoid the "Black Box" problem, we use SHAP values to show the contribution of each feature. The larger the SHAP value, the higher its contribution to the positive prediction. This allows staff to understand the concrete reasoning behind the AI's decision.
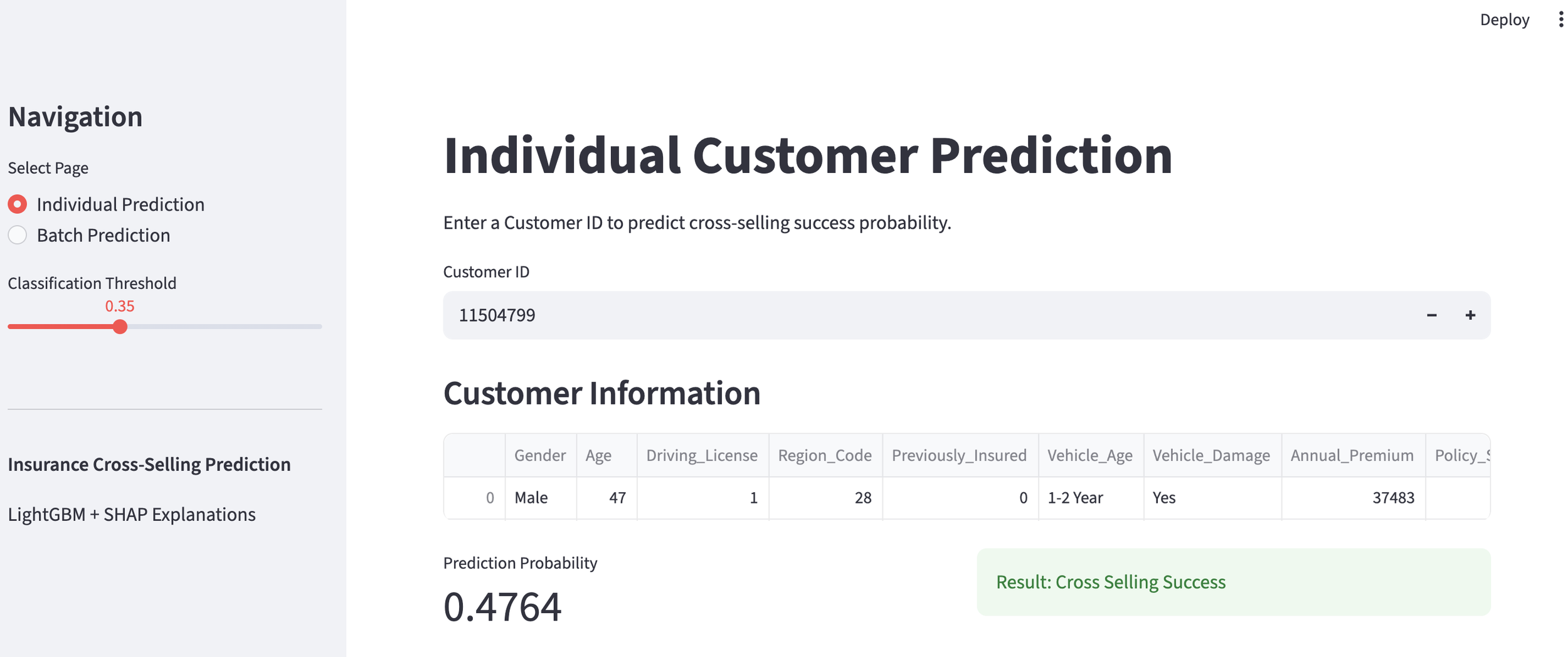
customer predicted to be success
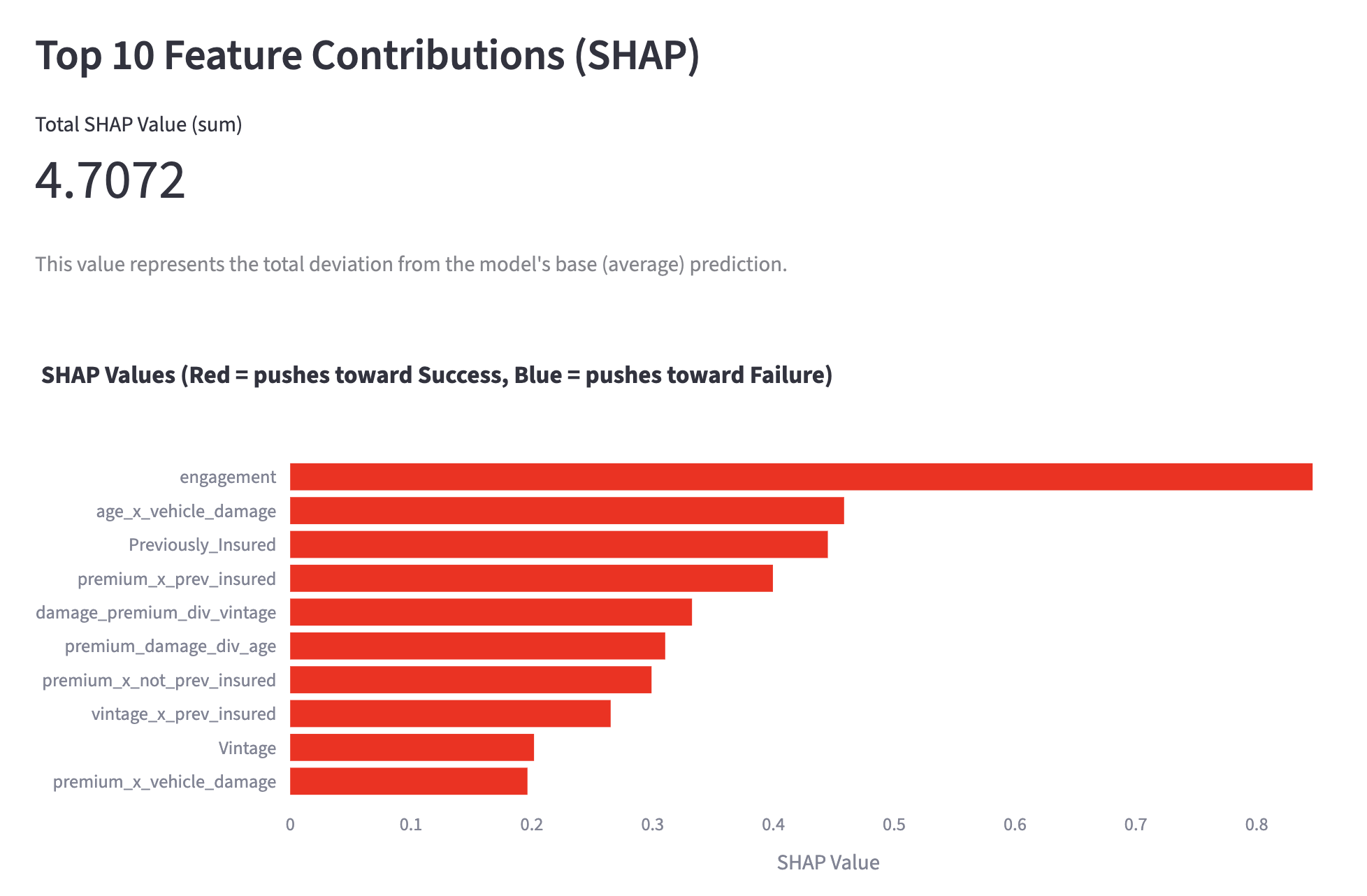
feature contribution
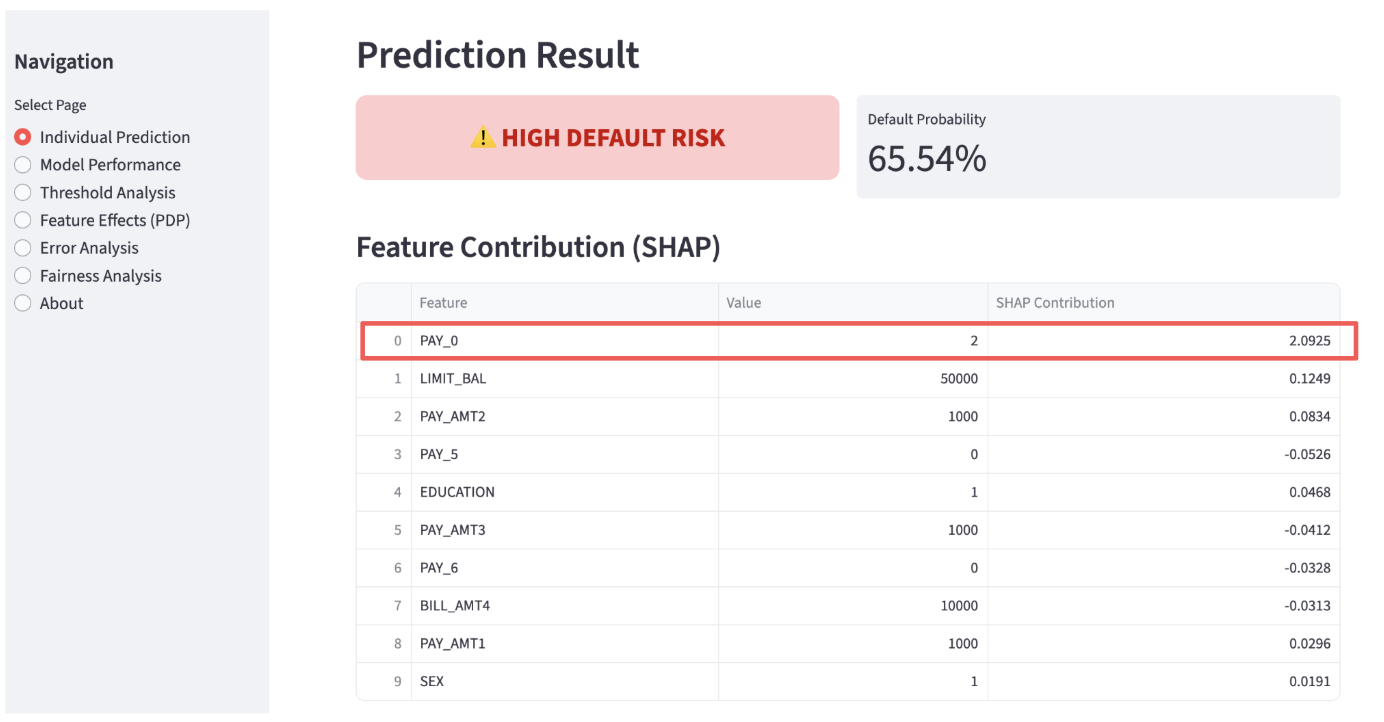
Conversely, for customers predicted to fail (probability below 35%), the SHAP values indicate which factors are pulling the probability down.
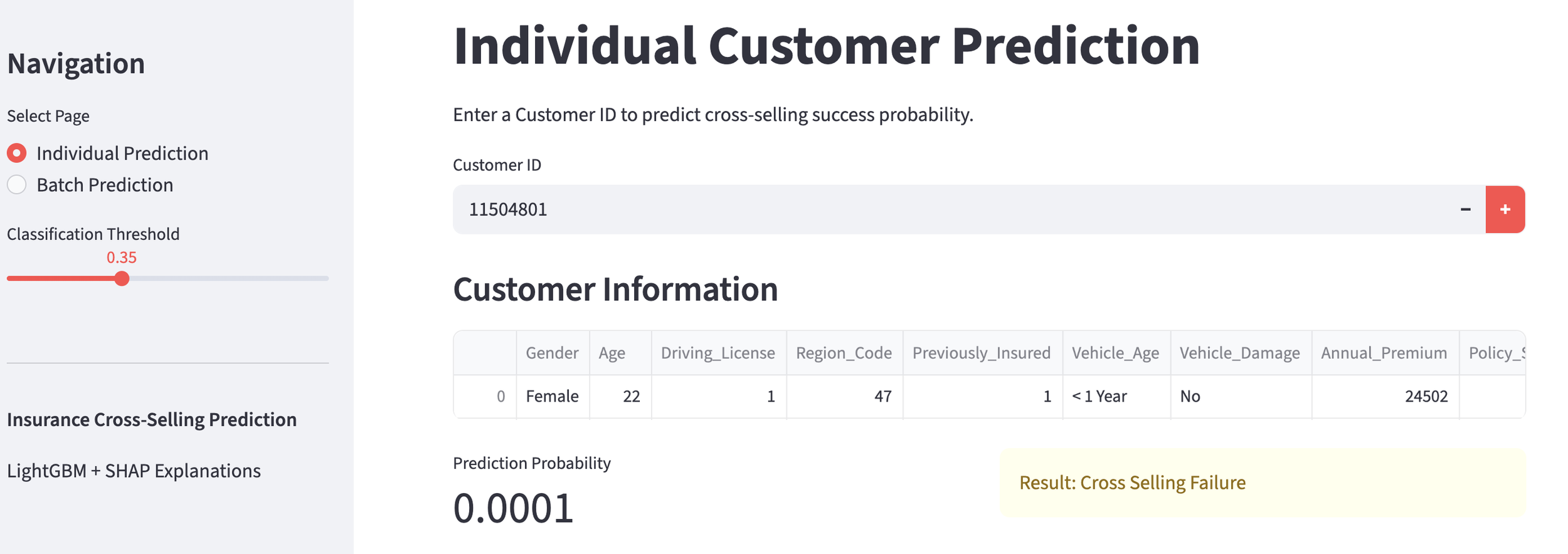
customer predicted to fail
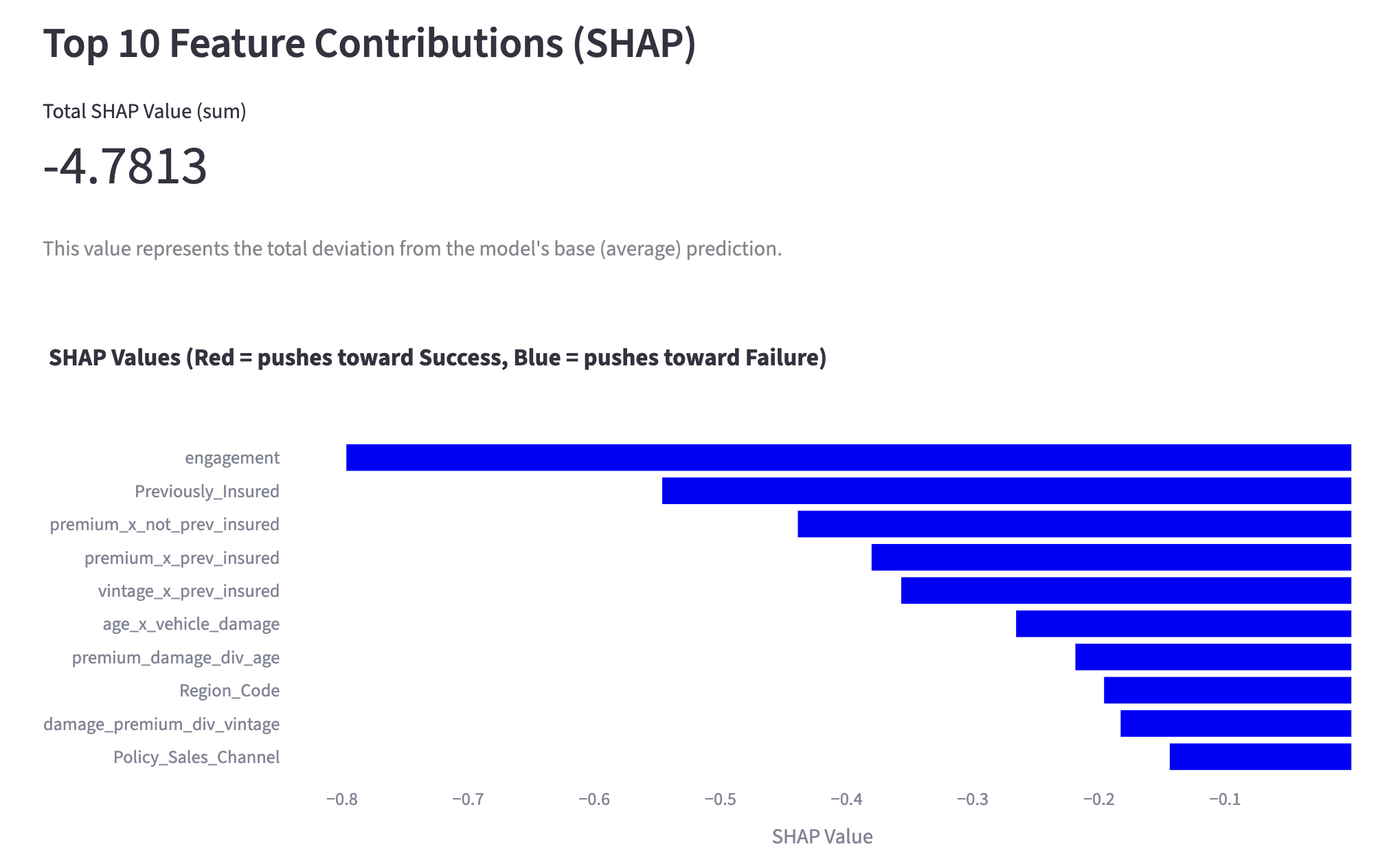
feature contribution
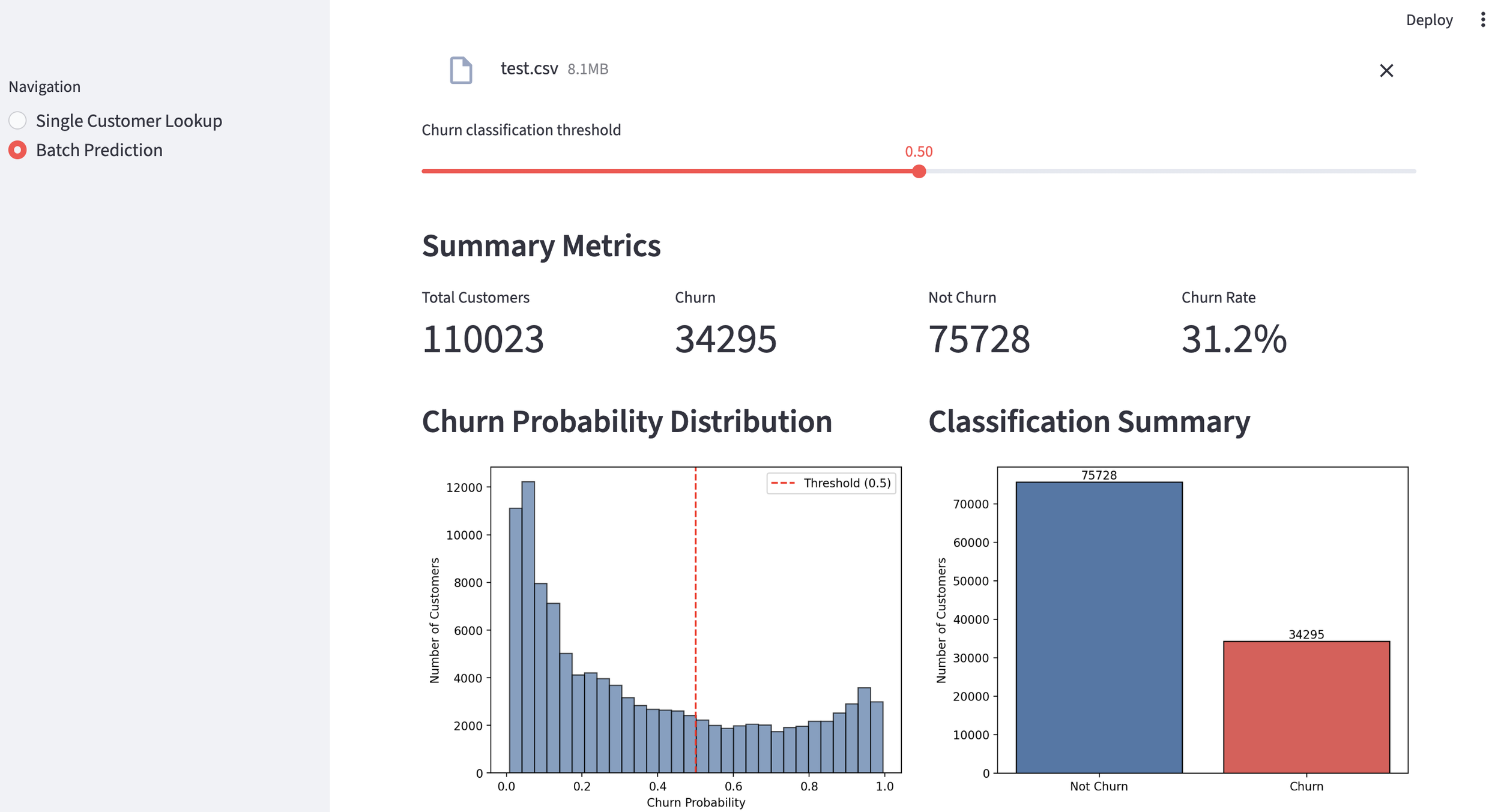
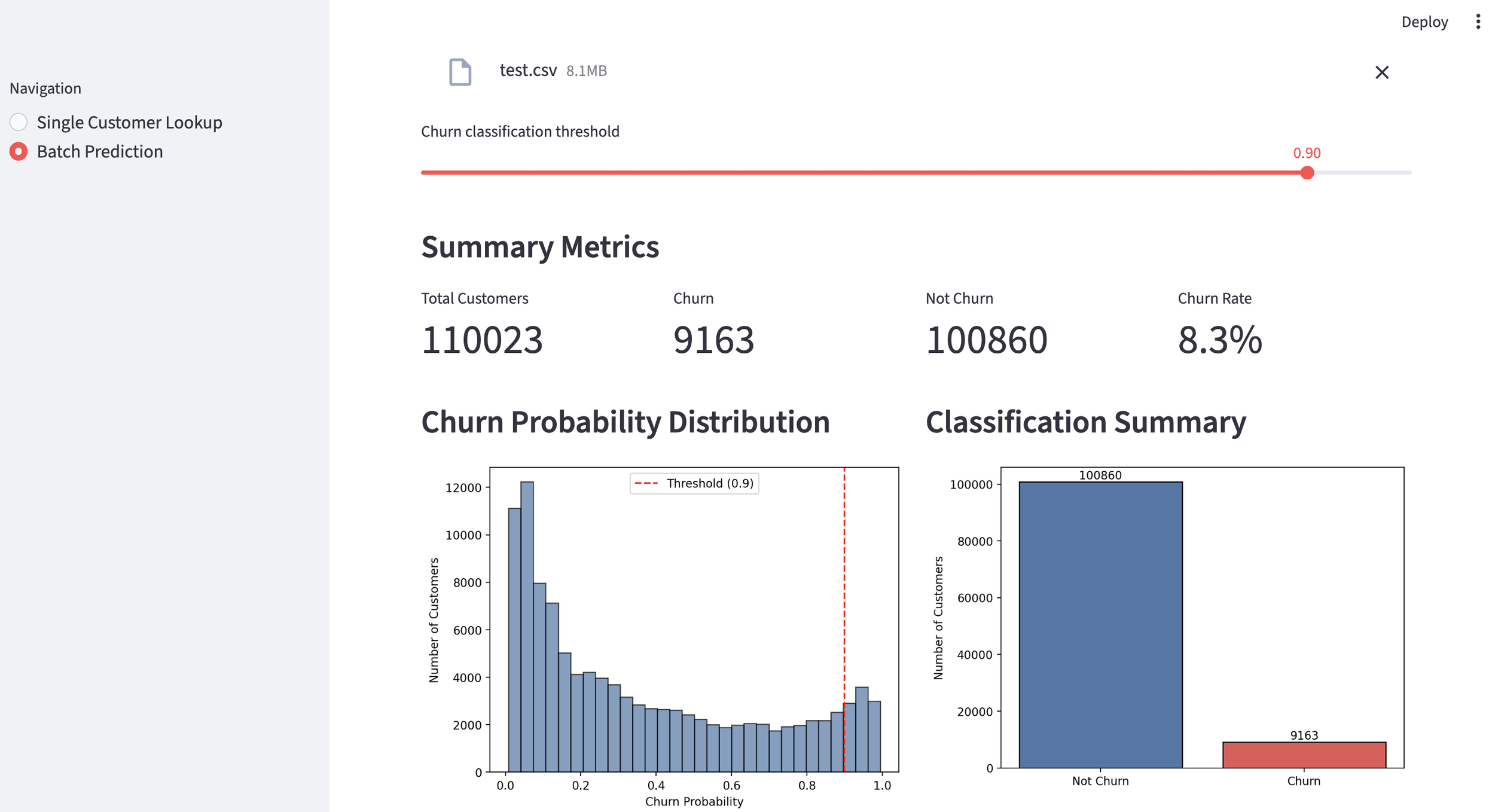
Customer portfolio Analysis
We can also analyze the "Cross-Sell Success Rate" across an entire customer portfolio. In this demo, we imported a CSV of 30,000 customers. With the threshold set at 35%, the model identified 3,708 potential targets. By adjusting the threshold, marketing teams can narrow or broaden their focus for specific campaigns. The dashboard also displays the overall probability distribution across the entire dataset.
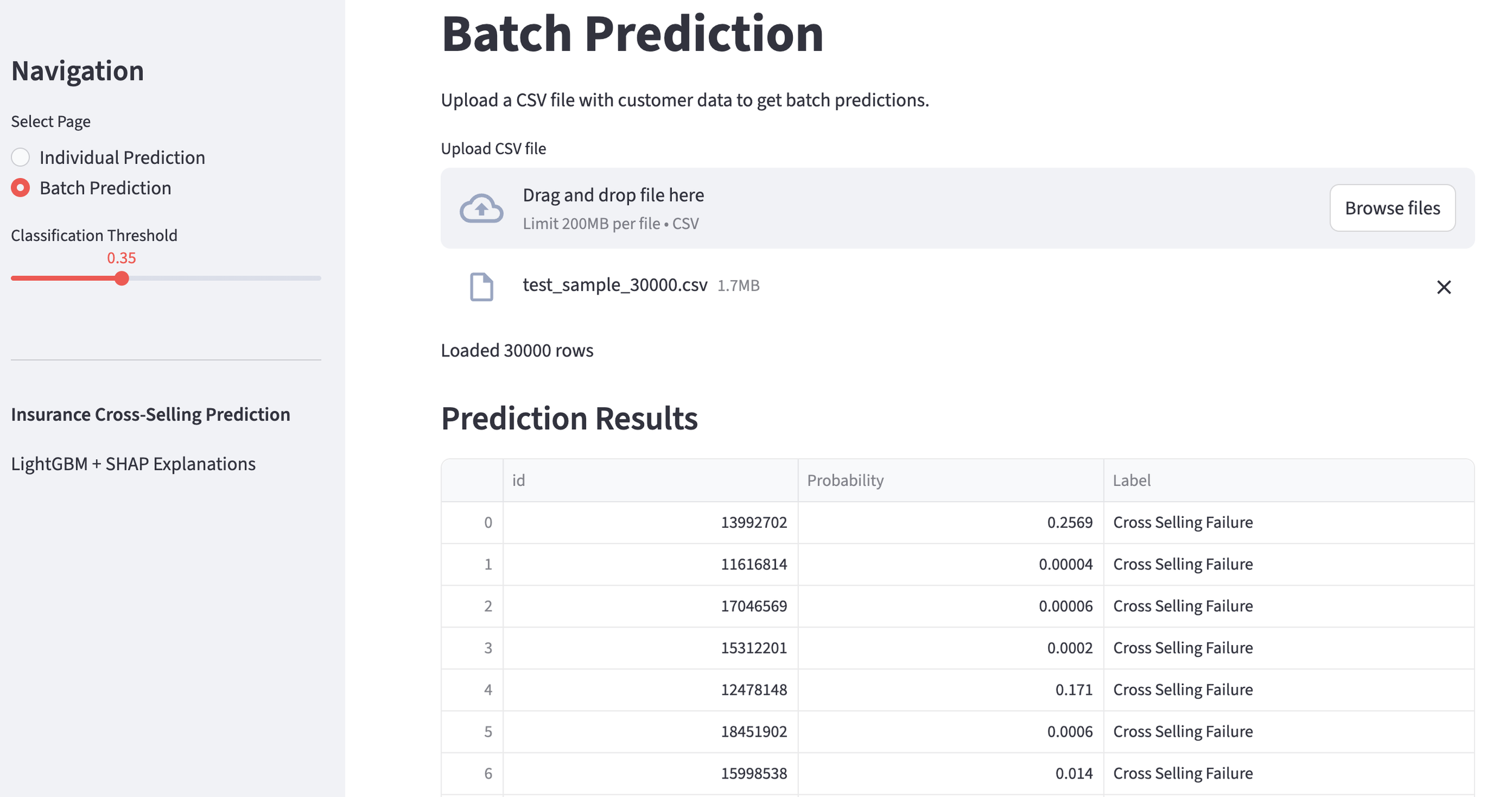
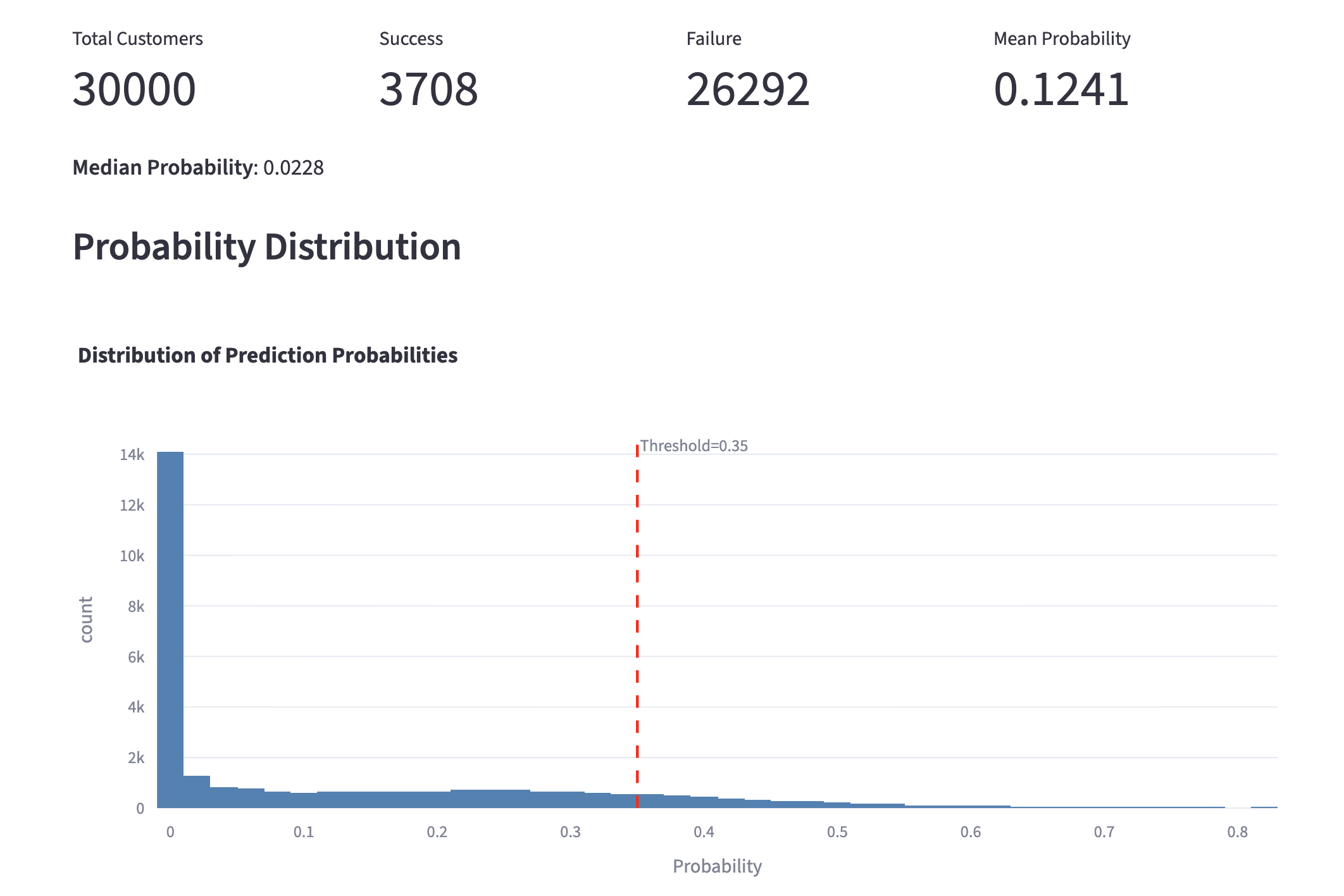
probability distribution
4. Business Impact
This high-precision model provides sales representatives with a prioritized "Hot Lead" list. Thanks to the Streamlit-based GUI, non-technical staff can execute batch predictions and verify the reasoning via SHAP instantly. This is the definition of Data-Driven Marketing.
Conclusion
The synergy between Opus 4.6 and human expertise is redefining the speed of machine learning development and implementation. The potential is, quite frankly, staggering. At TOSHI STATS, we will continue to explore innovations in this field.
Stay tuned!
1) Introducing Claude Opus 4.6, Anthropic, Feb 5 2026
2) Binary Classification of Insurance Cross Selling, Walter Reade and Ashley Chow, Kaggle
You can enjoy our video news ToshiStats-AI from this link, too!
Copyright © 2026 Toshifumi Kuga. All right reserved
Notice: ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the codes and the software.