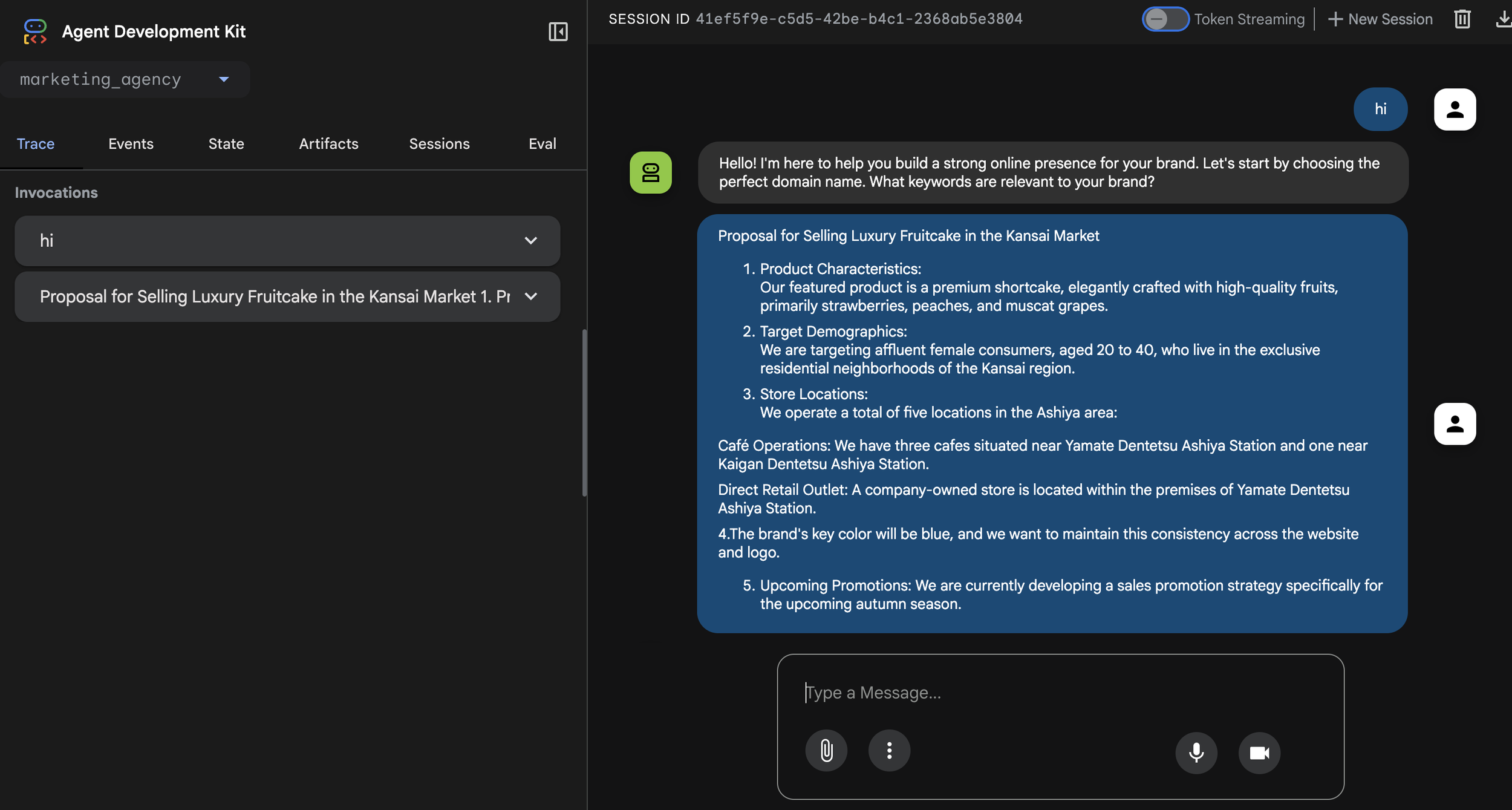
Just fresh off the heels of last week's new model release, Google has debuted yet another new image generation model: Nano Banana Pro (Gemini 3 Pro Image). Rumors on the street say it boasts incredible performance. So, let's dive in and test it out to see its potential capabilities.
1. The Latest Tokyo Fashion Trends
Fashion evolves with every season, and keeping up with the trends can be a challenge. However, the internet is overflowing with the latest style information. I figured that by feeding this real-time data into generative AI, we could generate images of models wearing the styles currently in vogue. Let's give it a try. Below is the original image of the model. She is wearing an outfit typical of Japanese autumn.

Original Image
I fed this original image and the prompt "Perform Google Search for current Tokyo fashion trends for 20s lady and apply that style to the model in the attached photo. 4 images are needed." into Nano Banana Pro.

Generated Images
The same model appears in all four images, maintaining consistency. Furthermore, the latest fashion trends have been incorporated thanks to Google Search. This is wonderful. Nano Banana Pro's Grounding feature using Google Search is excellent. As the model updates in the future, we can expect the accuracy of capturing trendy fashion to improve even further.
2. Creating a Signature Cafe Menu
Next, I want to devise a set menu featuring shortcake and coffee for opening a cafe in Ashiya, a high-end residential area in Japan. For this one too, I prepared a prompt to generate the image after researching currently popular cakes using Google Search.
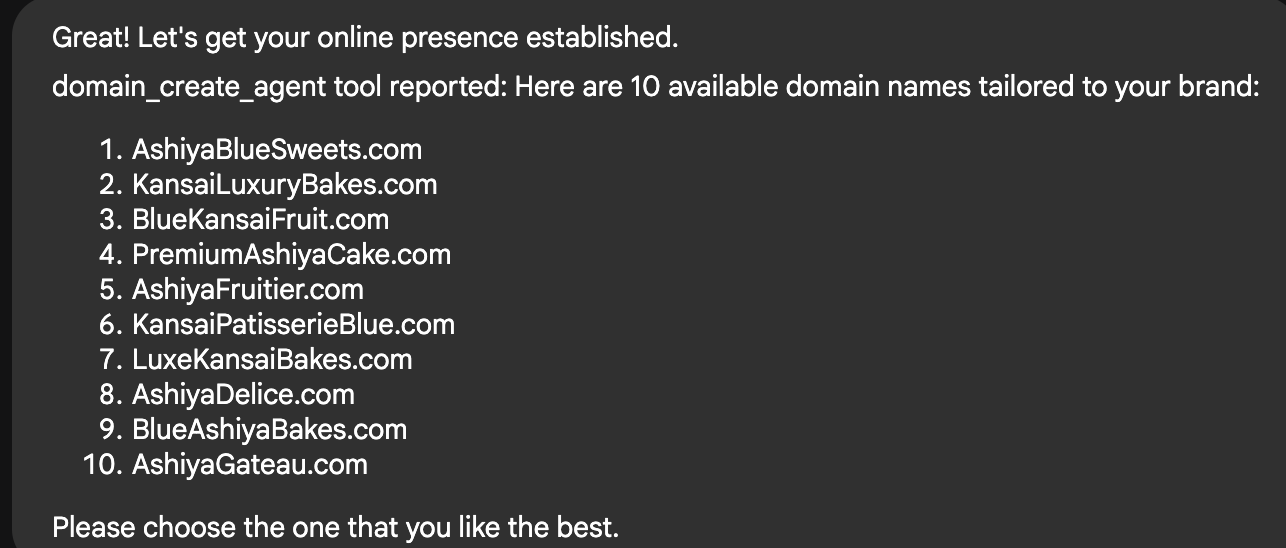
"I am opening a cafe in Ashiya, Japan, featuring a fruit shortcake and coffee set as the signature dish. Use Google Search to identify current cake trends in Ashiya City. Then, create a high-quality menu image for this set that includes a description and price in English, incorporating the local trends."
I generated the following Japanese and English versions of the menu.

English Version

Japanese Version
Both the Japanese and English text are perfect. I think this is a huge leap forward, especially since AI image generation has struggled to correctly render local languages like Japanese until now. I’m sure it will work well with other local languages too. It looks like Nano Banana Pro will be able to perform globally, regardless of language.
3. 3D Visualization of Loss Functions
Raising the abstraction level a bit, I want to execute a 3D visualization of a loss function—a topic often discussed when building targeting models for marketing—and clearly explain the concept of the gradient descent method. Nano Banana Pro can understand even theoretical and highly abstract phenomena like loss functions and map them in 3D. Below is the result. You can see at a glance how the parameters get stuck in a local minimum and cannot reach the point where the loss function is at its global minimum. Amazing.
Gradient Descent Method
How was it? Even from these few experiments, the excellence of Nano Banana Pro is clear. I have a hunch that Nano Banana Pro is going to change the very methods of digital marketing. I felt particularly strong potential in the Grounding feature using Google Search. I plan to cover Nano Banana Pro again in the near future.
That’s all for today. Stay tuned!
You can enjoy our video news ToshiStats-AI from this link, too!
1) Introducing Nano Banana Pro, Google, 20 Nov 2025
Copyright © 2025 Toshifumi Kuga. All right reserved
Notice: ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the codes and the software.