2026 has officially begun! The AI community is already abuzz with talk of "agentic coding" using ClaudeCode + Opus 4.5. I decided to build an actual application myself to test the potential of this combination. Let’s dive in.
1. ClaudeCode + Opus 4.5
These are the coding assistant and frontier model from Anthropic, respectively, both renowned for their strength in coding tasks. I imagine many will use them integrated into an IDE like VS Code, as shown below. You can see the selected model is Opus 4.5. Also, notice the "plan mode" indicator at the bottom.
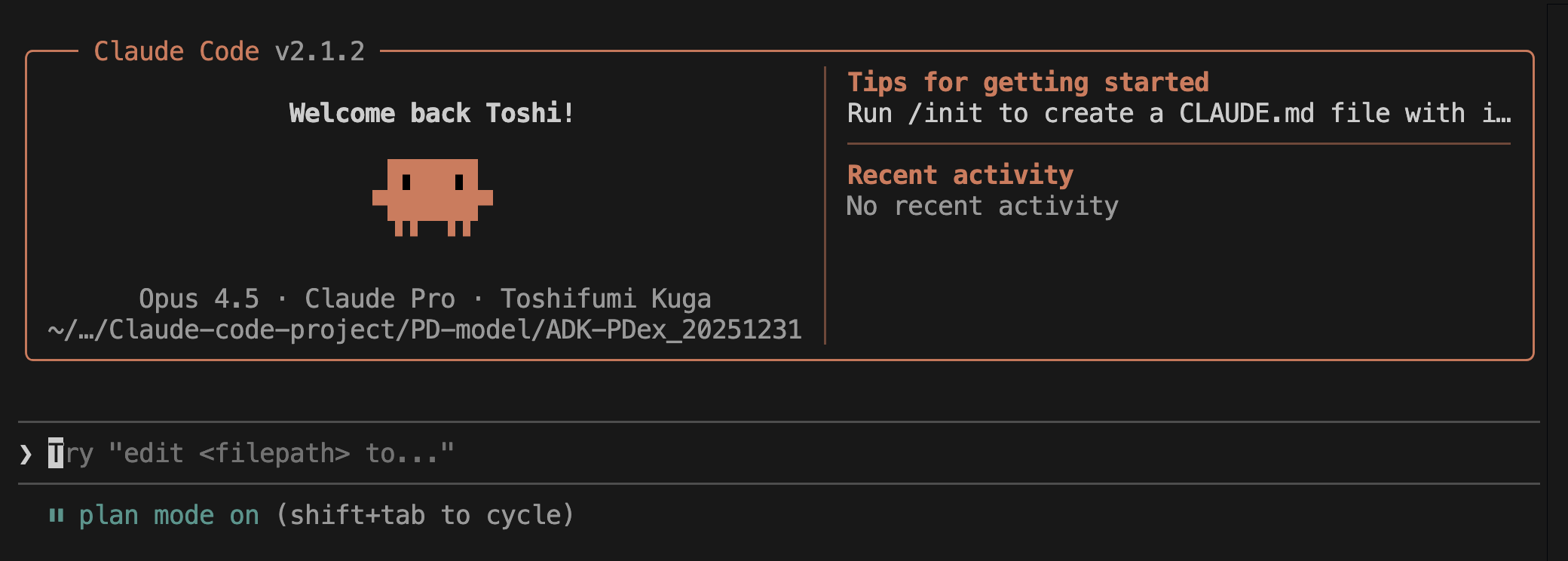
ClaudeCode
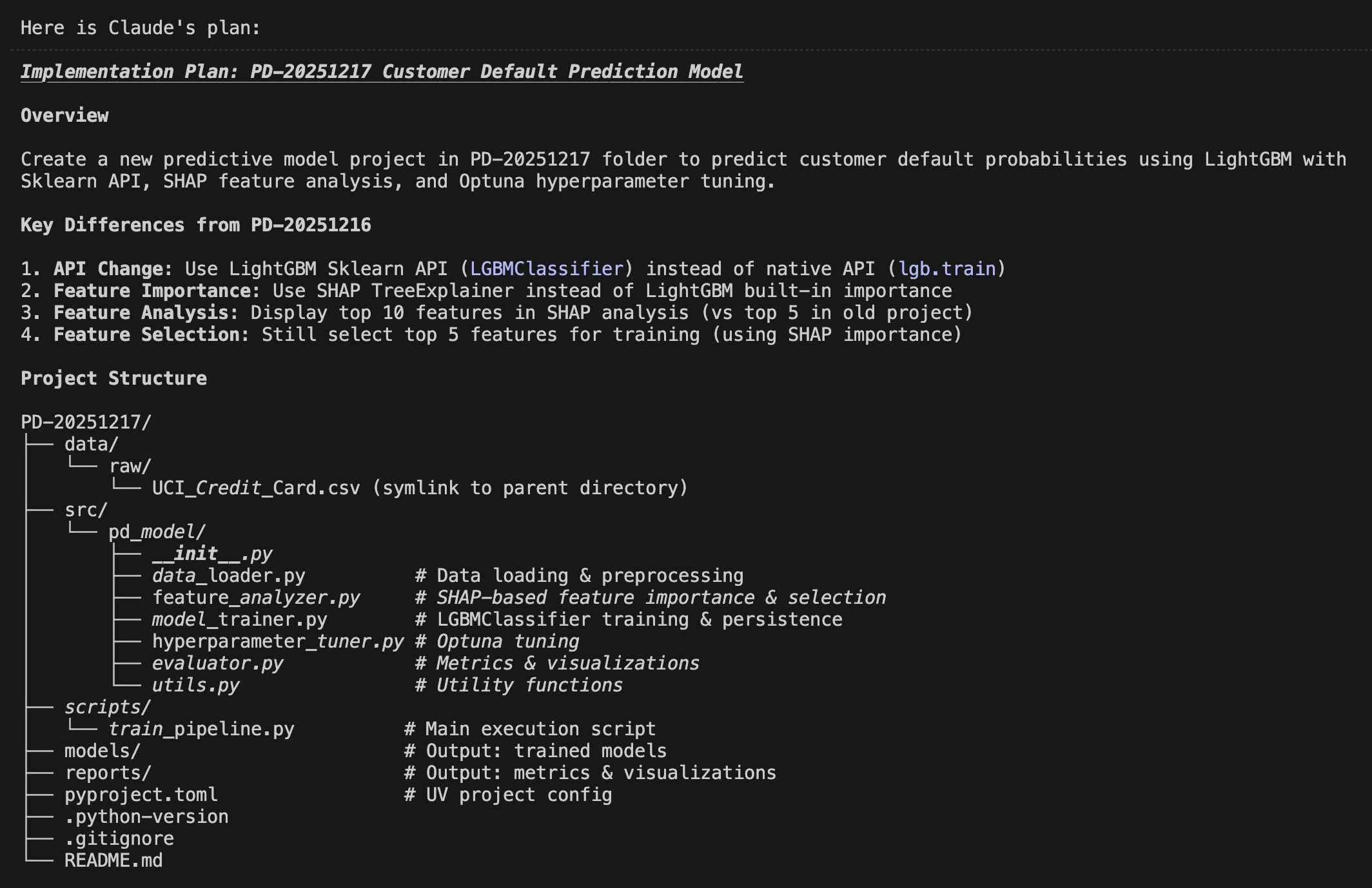
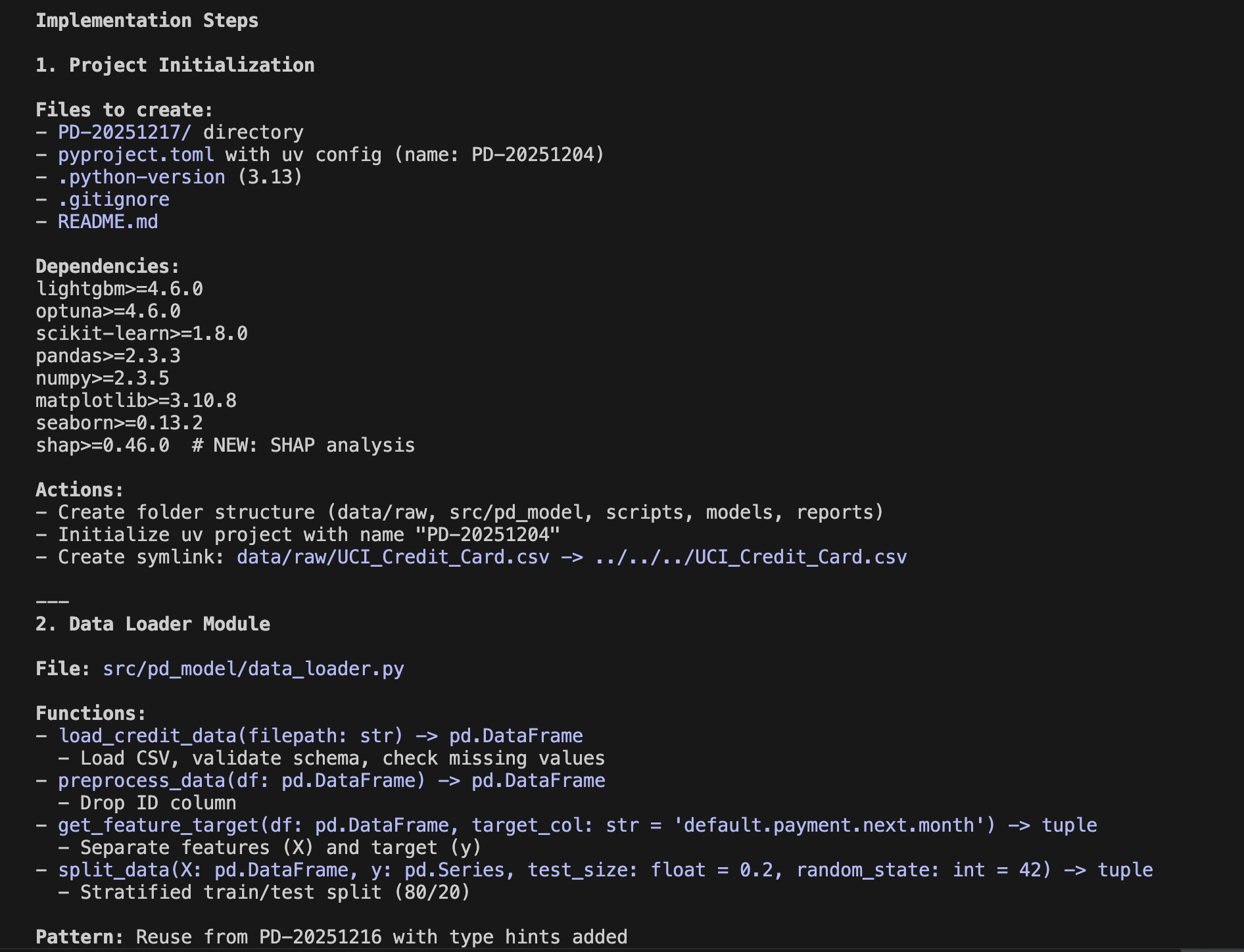
Here, a data scientist inputs a prompt detailing exactly what they want to develop. The system then enters "plan mode" and generates an implementation plan like the following. The actual output is quite long, but here is the summary:

Implementation Plan
The goal this time is to create an application that combines machine learning and Generative AI, as described above. Once you agree to this implementation plan, the actual coding begins.
2. Completion of the AI App with GUI
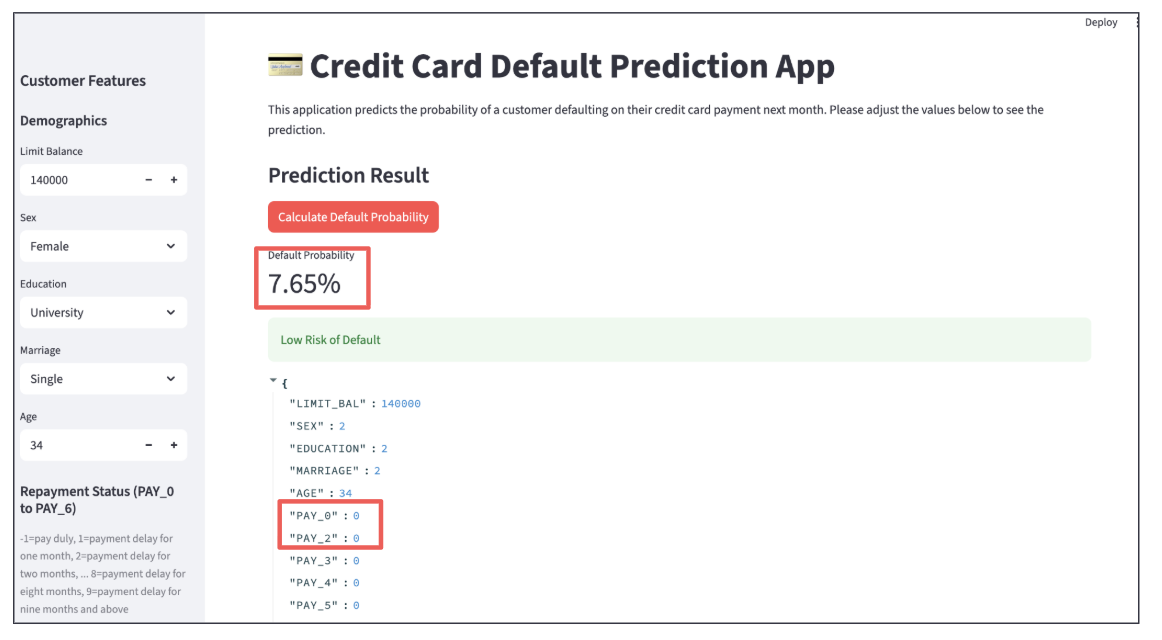
In this completed app, you can input customer data via the screen below to calculate the probability of default, which can then be used to assess loan eligibility.
The first customer shows low risk, so a loan appears feasible.
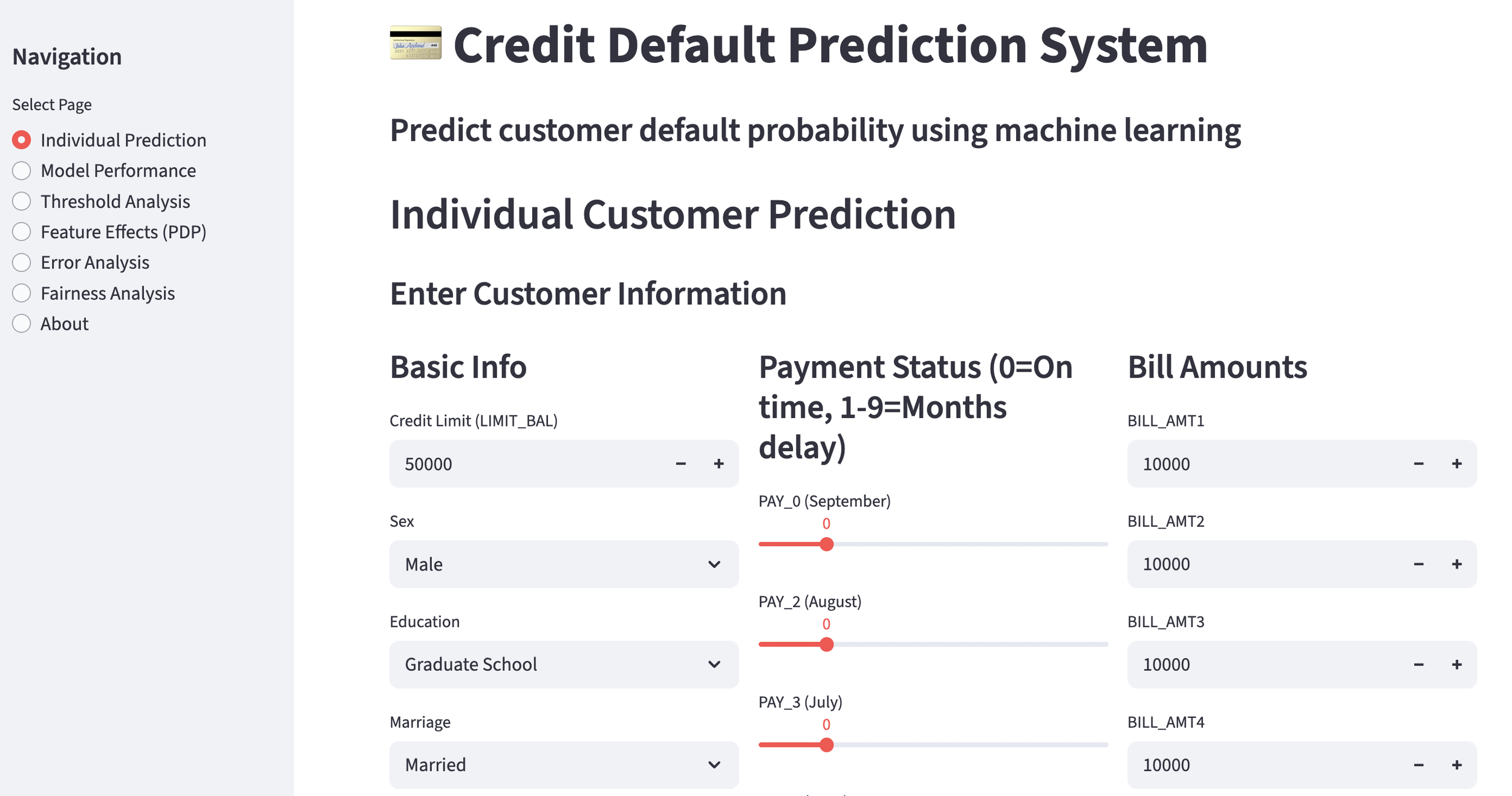
Input Screen
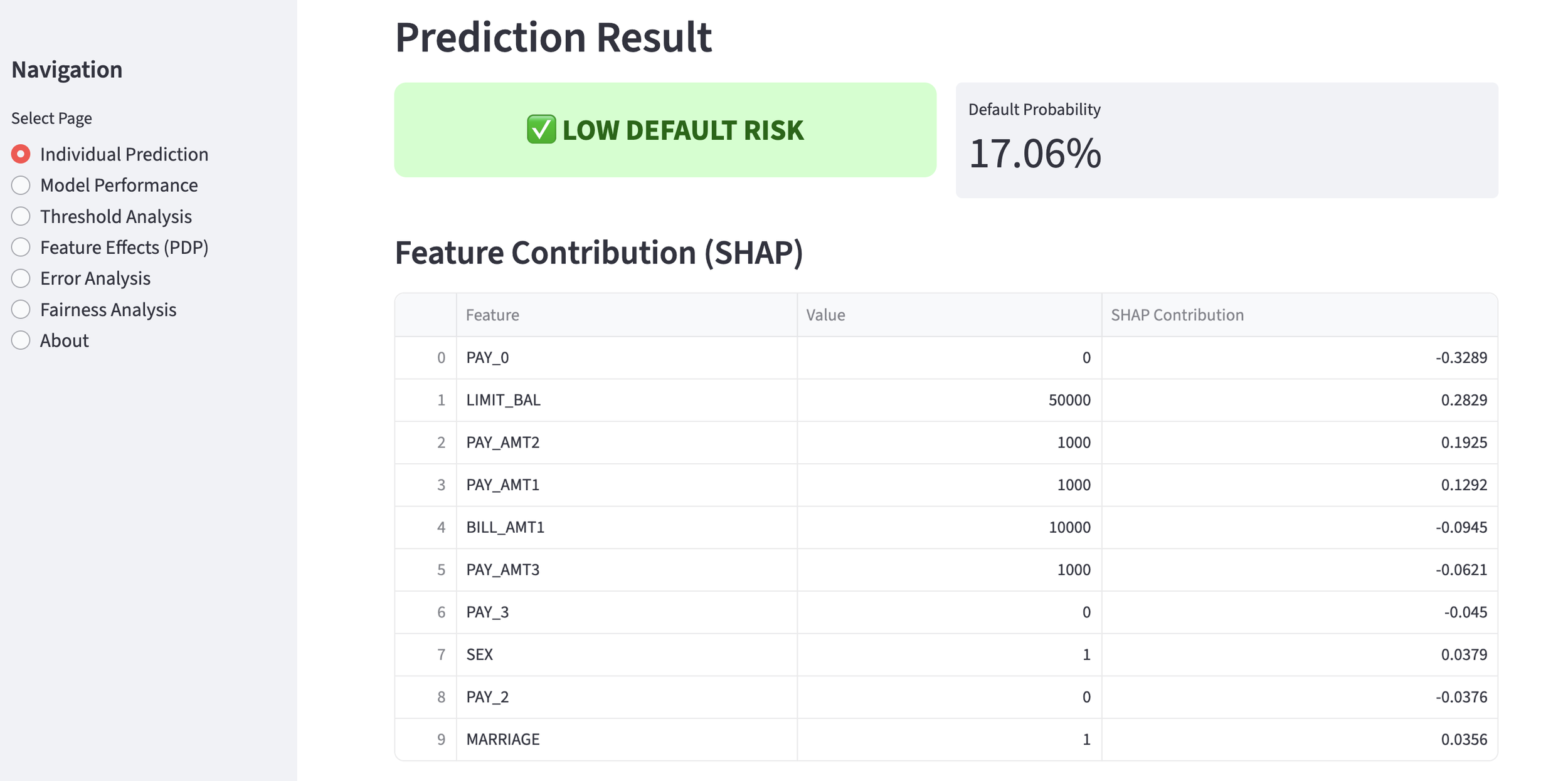
Default Probability 1
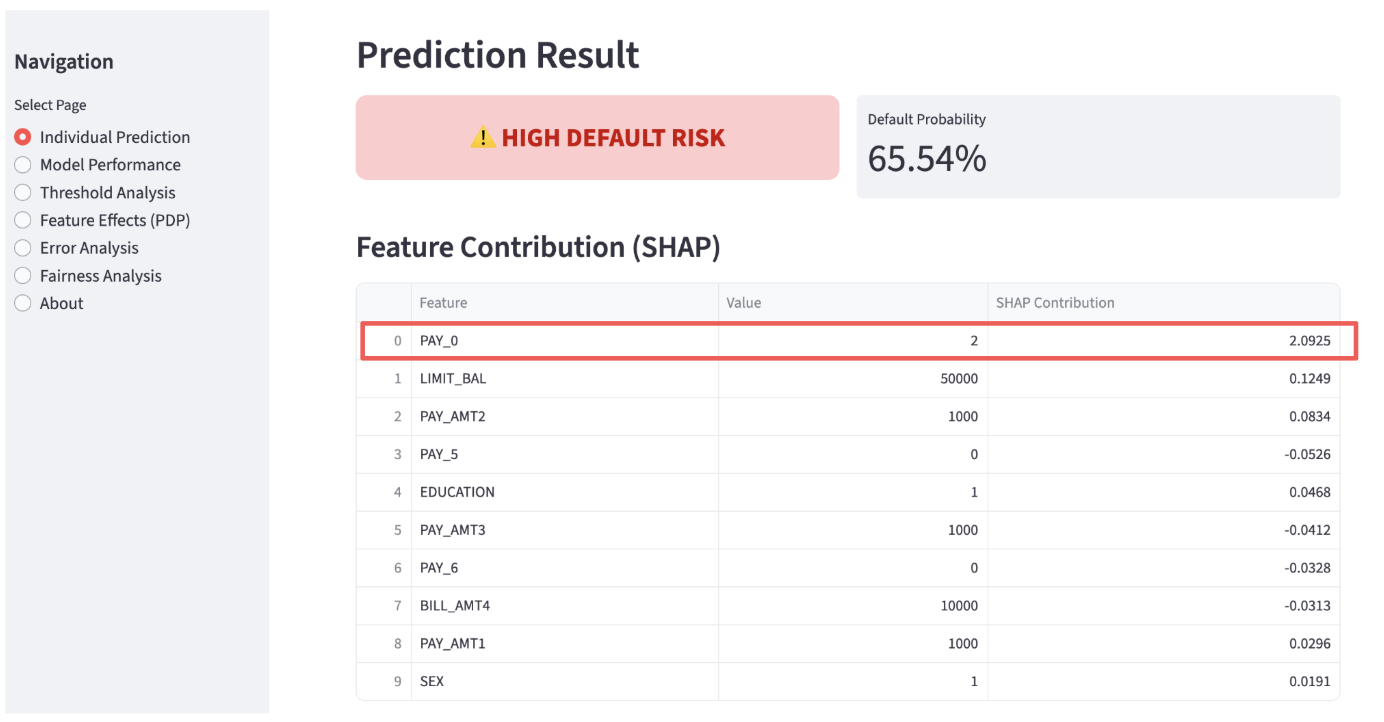
Default Probability 2
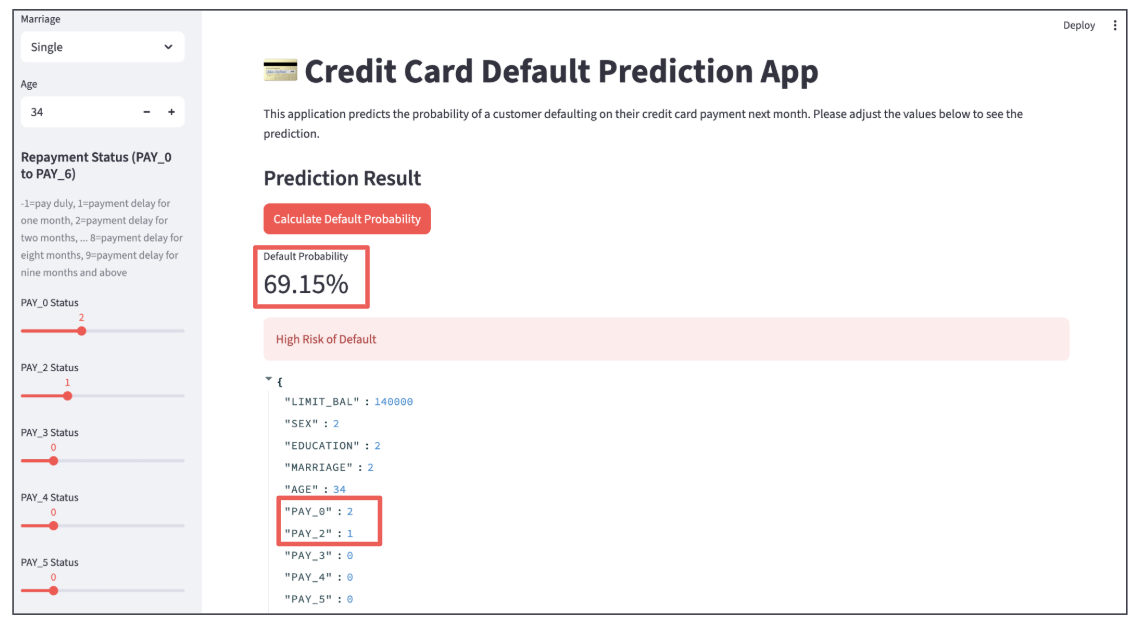
For the second customer, as highlighted in the red frame, the payment status shows a 2-month delay. The probability of default skyrockets to 65.54%. This is a no-go for a loan.
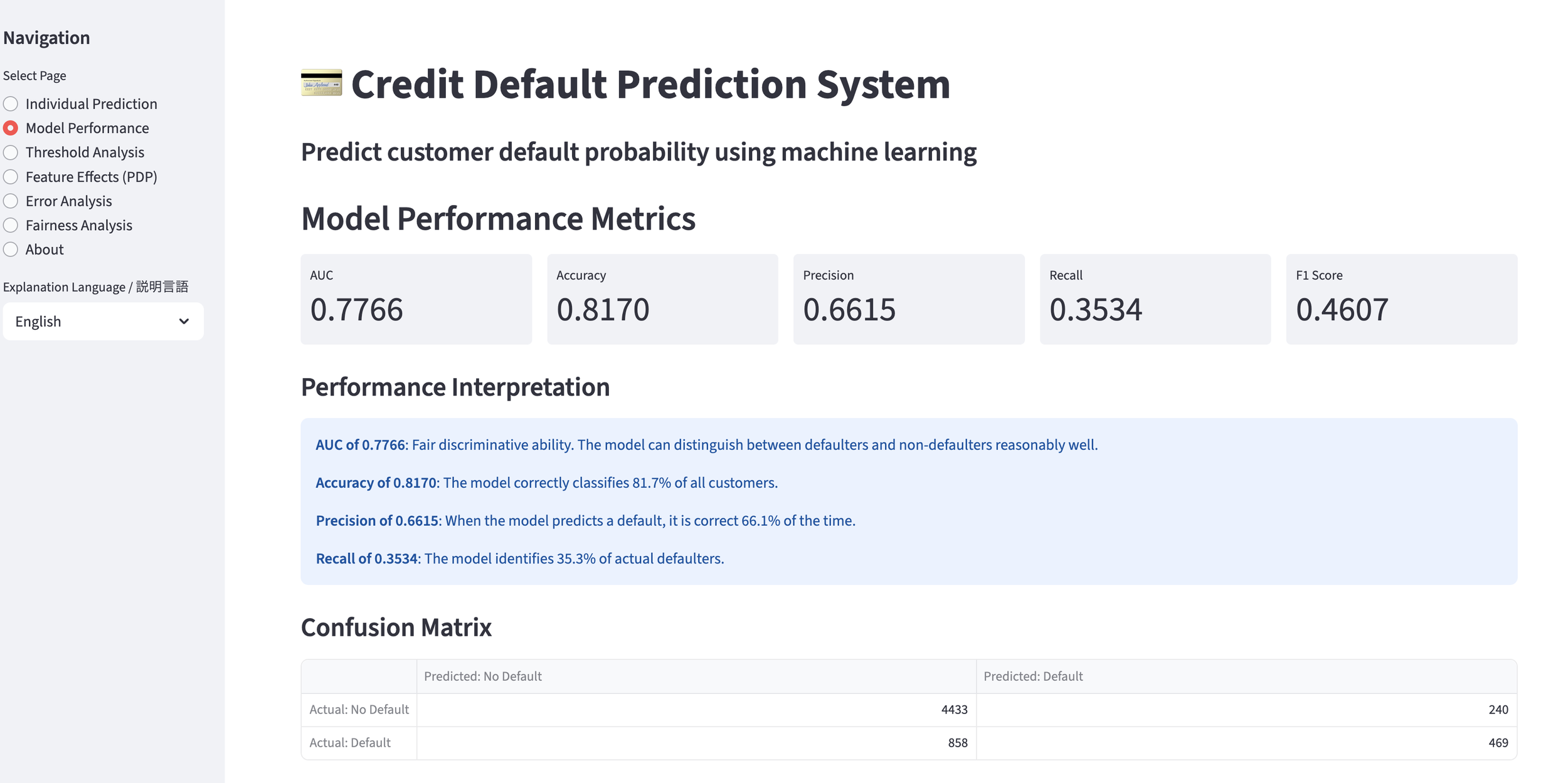
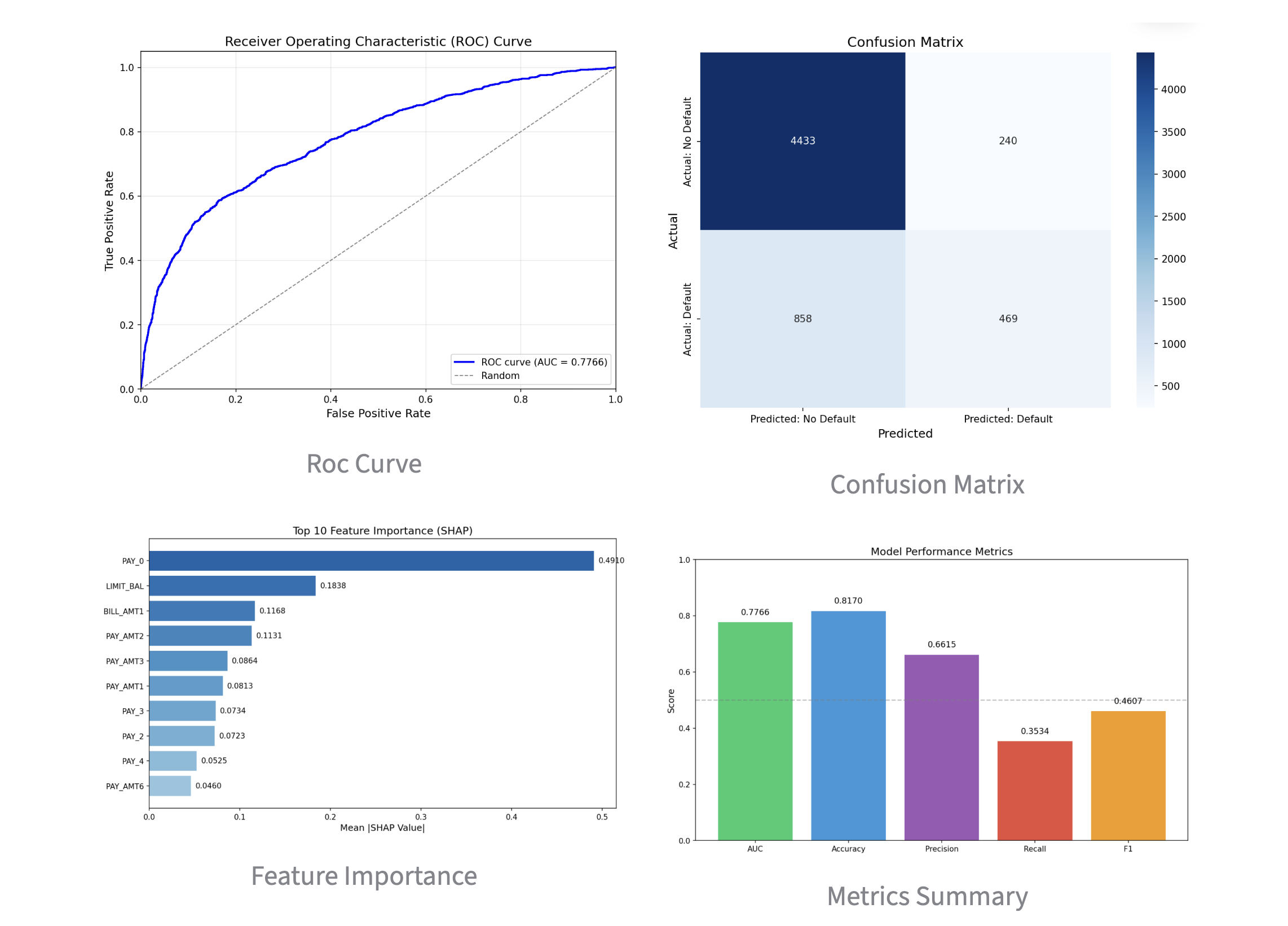
3. Validating Model Accuracy on a Separate Screen
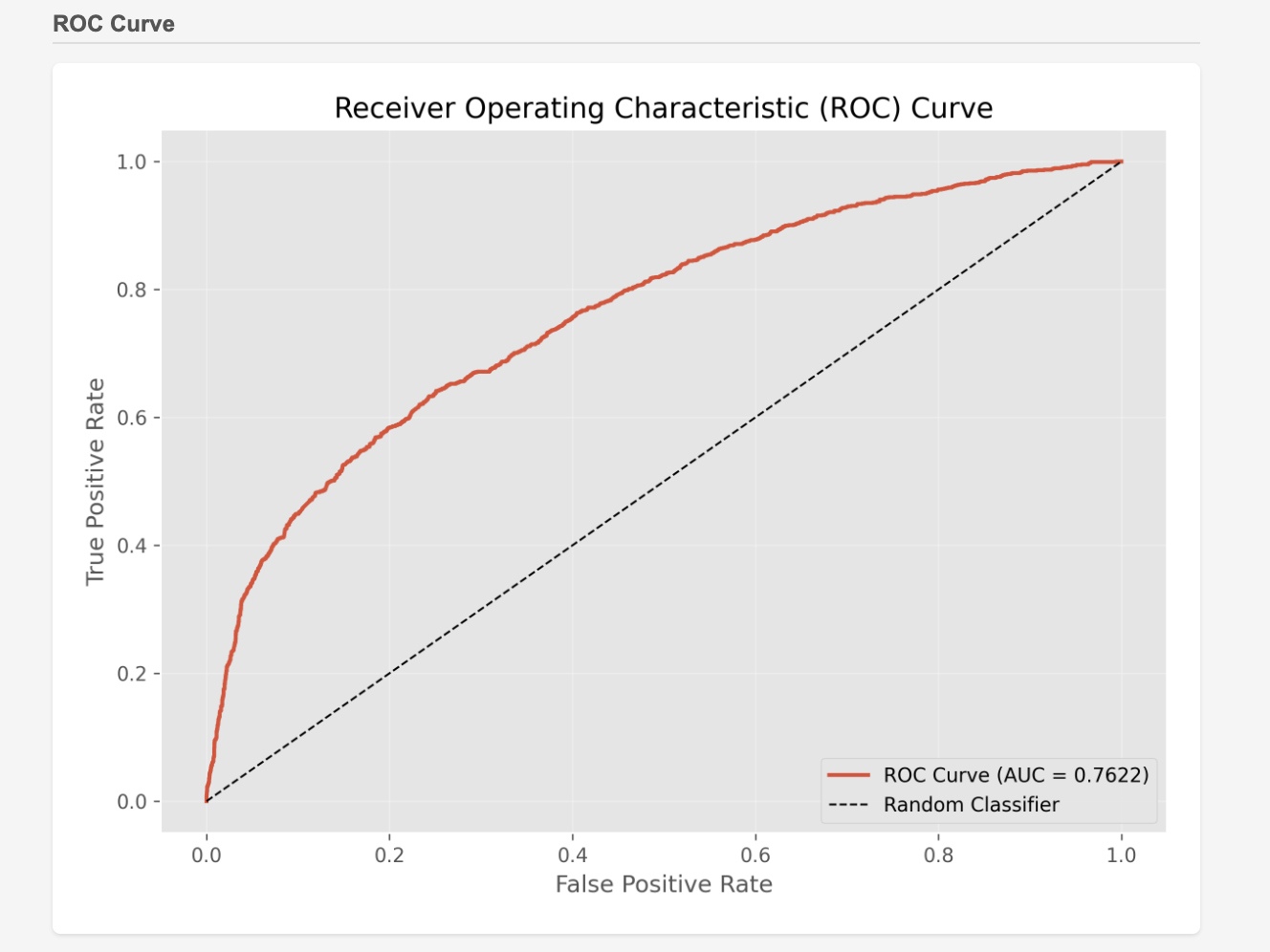
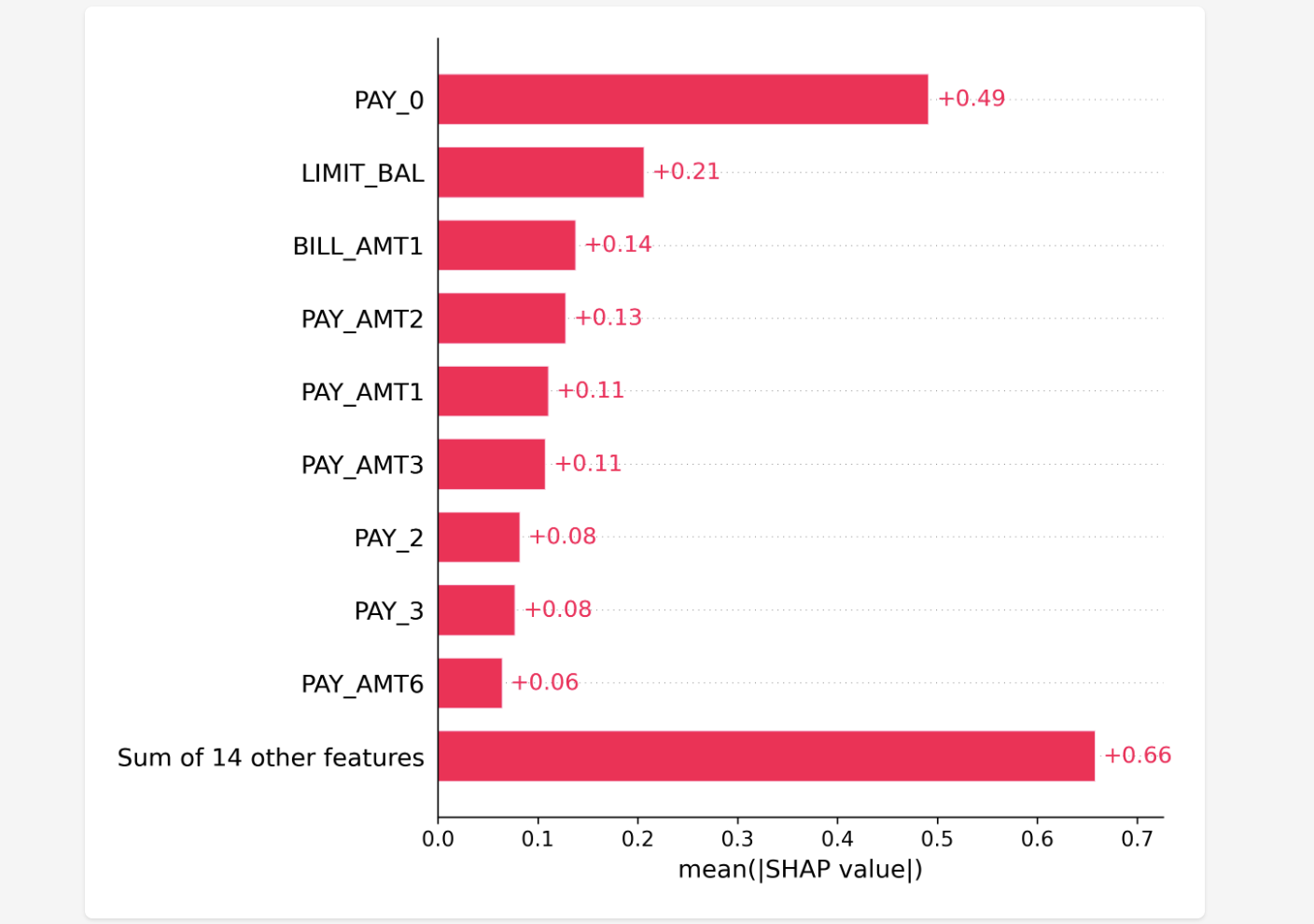
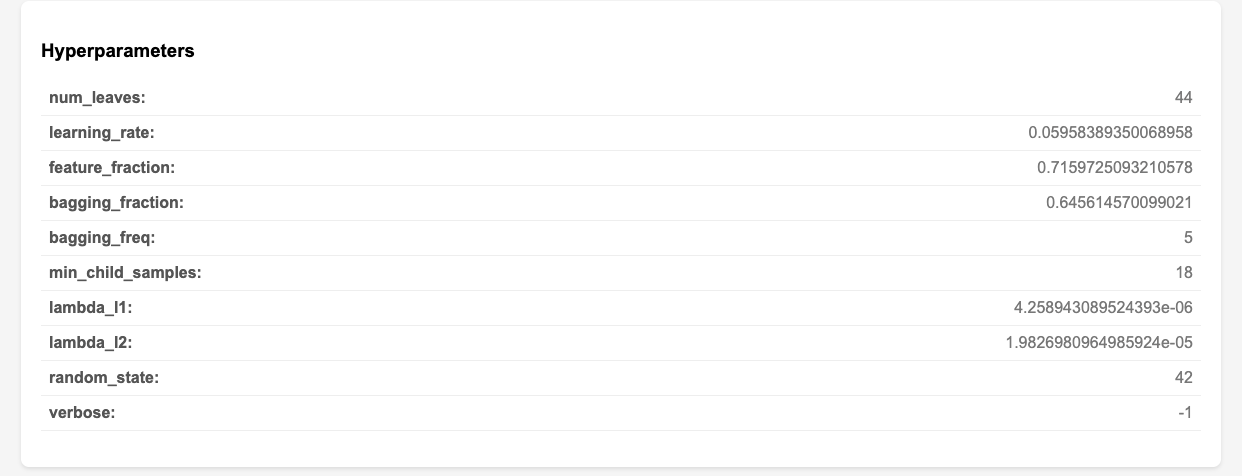
This screen displays the metrics for the constructed prediction model, allowing you to gauge its accuracy. While figures like AUC are bread and butter for experts, they might be a bit difficult for general business users to grasp.
To address this, I decided to include natural language explanations. By leveraging Generative AI, implementing multilingual support is relatively straightforward.

Switching the setting changes the text from English to Japanese. Of course, support for other languages could be added with further development.

While I used Opus 4.5 during the development phase, this application uses an open-source Generative AI model internally. This allows it to function completely disconnected from the internet—making it ideal even for enterprises with strict security requirements.
So, what are your thoughts?
An application with this rich feature set and a high-precision machine learning model was completed entirely with no-code. I didn't write a single line of code this time.
Opus 4.5 was truly impressive; the process never stalled due to syntax errors or similar issues. I can genuinely feel that the accuracy is on a completely different level compared to just six months ago. moving forward, it seems likely that "agentic coding" will become the standard starting point for creating new machine learning models and GenAI apps. It feels like PoC-level projects could now be knocked out in a matter of days.
I’m looking forward to building many more things. That’s all for today.
Stay tuned!
You can enjoy our video news ToshiStats-AI from this link, too!
Copyright © 2026 Toshifumi Kuga. All right reserved
Notice: ToshiStats Co., Ltd. and I do not accept any responsibility or liability for loss or damage occasioned to any person or property through using materials, instructions, methods, algorithms or ideas contained herein, or acting or refraining from acting as a result of such use. ToshiStats Co., Ltd. and I expressly disclaim all implied warranties, including merchantability or fitness for any particular purpose. There will be no duty on ToshiStats Co., Ltd. and me to correct any errors or defects in the codes and the software.